Generative AI
Building AI-powered features in the Software Factory
IndiciumTo support the use of generative AI in your applications, four Large Language Model (LLM) connectors are available that you can use in your system flows (see the Create a system flow guide). They connect to an external API configured through your Generative AI Provider in the Software Factory. The prompts are sent to the Generative AI provider and the LLM's response is sent back.
The LLM connectors open a world of new possibilities to improve your processes. You can use them, for example, to:
- Generate text based on a few keywords
- Summarize text
- Classify text (extract the subject or tags from a text)
- Analyze the sentiment of a text
- Answer questions
- Translate text to another language
When not to use an LLM
LLMs are not suitable for:
- Statistical analysis
- Planning problems (e.g., routes, schedules)
- Evaluating rules on structured data
- Tasks that leave no room for inaccuracies
- Enforcing business rules
- etc.
The following LLM connectors are available:
- LLM Chat completion - use this connector to build a chat conversation between a user and a Large Language Model (LLM).
- LLM Completion - this connector can suggest how to complete a provided text. You can use it, for example, to complete product descriptions, draft emails, or generate code.
- LLM Instruction - this connector can transform text following your instruction. It can, for example, summarize, translate, change the formality of, or remove sentiment from a text.
- LLM Embedding - this connector can find semantically related texts.
Each LLM connector in the topics below contains an example of how you could use it. For more examples, see Potential use cases for LLM connectors.
You can set up a generative AI provider for different purposes:
-
If you want to build features that use generative AI in your model or branch, you must set up a generative AI provider for a branch in the Software Factory. For more information, see Set up a generative AI provider for a branch. What you set up here is used as the default, however you can override these settings for:
- Runtime configurations for development or testing purposes in menu Maintenance > Runtime configurations > tab Generative AI provider. For more information, see Generative AI for a runtime configuration.
- Applications in IAM in menu Authorization > Applications > tab General settings > tab Generative AI providers. For more information, see Generative AI for an application.
-
If you want to use AI features in the Software Factory, such as AI code reviews or AI-powered enrichments, you must set this up in IAM. For more information, see Enable generative AI for the Thinkwise Platform.
Definitions for generative AI
Generative AI refers to a specific class of artificial intelligence techniques and models. These are designed to create or generate new content that is similar to, but not an exact copy of, existing data. The models can generate new content, such as text, images, music, and more, by learning patterns and structures from large datasets.
A Large Language Model (LLM) is an example of Generative AI. LLMs are large neural networks that are trained to predict the next token (word, punctuation, etc.) given some text. They are trained on very large amounts of data. You can instruct an LLM what to do with your text.
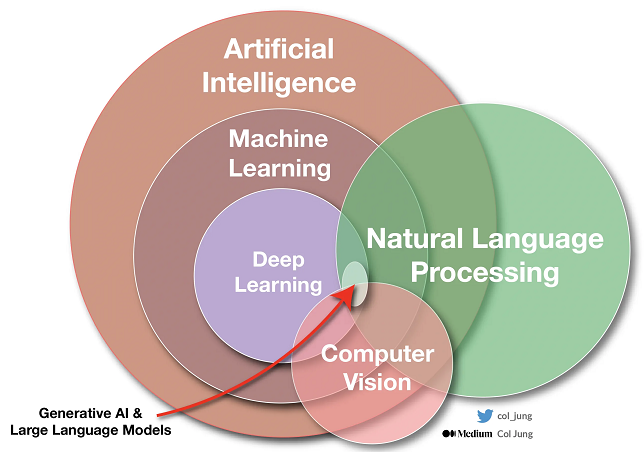 A visual explanation
A visual explanation
Prerequisites and limitations of LLMs
Before you start working with Large Language Models:
- Make sure that your customer's data is safe. Security and compliance with the applicable GDPR rules are your own responsibility.
- Use different accounts for development and production environments.
- Always check the outcomes. Results depend on your input and instructions.
- For the best performance, we recommend using a paid version of a generative AI provider, for example OpenAI's ChatGPT or Azure's OpenAI Service. If you are using an unpaid version, you may encounter errors due to insufficient rights.
Token limits
Be aware of token limits in models:
The different GPT models have different token limits. The whole conversation, all system, user, and assistant messages are used as input to the model. With ongoing conversations, you will eventually reach the token limit. Therefore, always keep track of the token length of the conversation, and when the count reaches the limit, delete items from the conversation to stay within limits.
For example, the standard gpt-3.5-turbo model has a limit of 4096 tokens. This limit is easily exceeded by filling the prompt with the contents of multiple emails.
Set up a generative AI provider for a branch
Software FactoryYou must set up a generative AI provider for a branch or a model to use LLM process flow connectors. You can set up multiple providers to separate LLM workloads across API keys or deployments. This is useful, for example, to optimize performance or to manage costs.
To ensure optimal performance, use a paid version of your generative AI provider. Free versions may cause applications errors, including those related to insufficient rights. See Prerequisites and limitations of LLMs for more details.
The generative AI provider you set up here is used as the default provider for the application that you synchronize to IAM.
To configure a generative AI provider for a branch:
menu Integration & AI > Generative AI
-
Enter a name in the field Generative AI provider.
-
Select a Provider type. The following providers are supported:
- OpenAI
- Azure OpenAI
- OpenAI compatible - use this option if you want to use a provider that is compatible with the OpenAI API format and standards. You can use providers such as Anthropic (Claude) or xAI (Grok). Here, you can also add any locally running LLM, giving you the flexibility to work with models hosted on your own infrastructure.
-
Complete the information in the group Authentication. Depending on the provider type, authentication options can be different. For more information, see Encrypt key values for generative AI providers.
-
If necessary, change the Settings for the models. These models are used for the different LLM connectors. For a full overview of the currently available models, see OpenAI Platform. Beware that changing to another model may break the compatibility. For example, you can probably safely change from
gpt-3.5-turbotogpt-4for the chat completion model. However, the same change for the embedding model will break the compatibility with the existing embeddings in your database.
- To override these settings for a specific runtime configuration (for development and testing): menu Maintenance > Runtime configurations > tab Generative AI. See Runtime configurations for more information.
- To override these settings for an application in IAM: menu Authorization > Applications > tab Generative AI. See Generative AI settings in IAM.
The tab Usage shows where the generative AI provider is being used. This can be helpful when, for example, you want to make a change to the generative AI provider and see what impact this might have. For more information on this generic feature, see Usage.
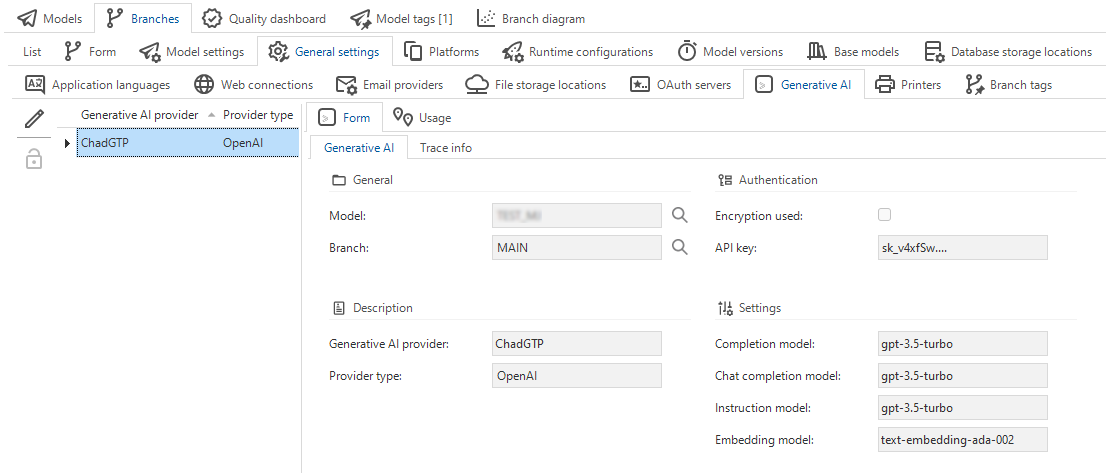 Configuring generative AI providers
Configuring generative AI providers
Encrypt key values for generative AI providers
3-tier IAM in the Universal GUIEncryption is only available in a 3-tier setup, where the Software Factory and IAM are used in the Universal GUI. It is not available for the Software Factory and IAM for the 2-tier Windows GUI because it requires Indicium support and configuration.
When you are working in a 3-tier environment, we advise you to encrypt the key values of your generative AI providers in the database. The default for your generative AI providers is set in the Software Factory. See Encryption for a branch.
To configure the generative AI provider encryption:
menu Authorization > Applications > tab Generative AI providers
Here you can:
 Set generative AI provider key values (encrypted) -
Set encrypted key values for your generative AI provider.
Set generative AI provider key values (encrypted) -
Set encrypted key values for your generative AI provider. Reset encrypted key values -
Reset the encrypted key values.
You may need to add unencrypted key values here afterward
to ensure that the generative AI provider keeps working.
Reset encrypted key values -
Reset the encrypted key values.
You may need to add unencrypted key values here afterward
to ensure that the generative AI provider keeps working.
Process flow connector - LLM Chat completion
| Starting point Universal GUI | Starting point Windows GUI | Starting point system flow (Indicium) | System flow action |
|---|---|---|---|
| - | - | + | + |
You can use the LLM Chat completion connector to build a chat conversation between a user and a Large Language Model (LLM).
Depending on your configuration, the history can remain available during the entire conversation and be reused in subsequent connector use. You could also use a user's previous history to set up the goal of the chat and to set the initial context for the chat using data from the application. This can be done invisibly to the user.
| Input parameters | |
|---|---|
| Chat history (optional) | A JSON array as formatted in the request, usually one system message followed by several user and assistant messages. You can modify this via logic to include any additional messages. |
| Prompt | The new message, usually a user message. It will be added to the chat history. |
| Max tokens (optional) | The maximum number of tokens. The default depends on the provider and model. See also Prerequisites and limitations of LLMs. |
| Output parameters | |
|---|---|
| Received chat message content | The reply from the LLM. |
| Chat history | The chat messages in JSON format with the received chat message appended for easy continuation of the chat. |
| Status code | 0 Successful -1 Unsuccessful (unknown) -2 Unsuccessful (no generative AI provider present) -3 Unsuccessful (no prompt) -4 Unsuccessful (invalid history). See the input parameter Chat history in the table above on how the chat history should be formatted. -10 Unsuccessful (no response) -11 Unsuccessful (access denied) -12 Unsuccessful (invalid request) -13 Unsuccessful (invalid response content) -14 Unsuccessful (throttling) -15 Unsuccessful (request timeout) -16 Unsuccessful (service error) -17 Unsuccessful (model not available) -18 Unsuccessful (invalid configuration) -19 Unsuccessful (function type not supported) |
| Error text | Errors from your generative AI provider. |
Example: Customer support with LLM Chat Completion
Context: a customer has sent two emails.
- The role (system) contains the instruction for the LLM.
- A customer support person (user) wants to help the customer fast without reading (long) emails or history.
- The connector (assistant) replies with a summary.
The application provides the LLM Chat Completion connector with an initial history: the system message, the emails making up the support ticket, and a prompt to give a summary. The user will see the most actionable information first: the summary and order number if provided. They can subsequently ask additional questions.
[
{
"role": "system",
"content": "You are a concise assistant that provides context to and answers questions about customer service tickets. These tickets consist of a number of emails. When asked for a summary, ALWAYS respond with \"order no:\" followed by the order number or \"not provided\" if not provided, and then respond with \"summary:\" followed by a one to two-sentence summary of the support ticket."
},
{
"role": "user",
"content": "email: Dear Customer Support,\n\nI am writing regarding an order that I recently placed on your website. I received the package yesterday, but unfortunately, it was missing an item that I had ordered.\n\nThe order number is #123456 and the missing item is a blue hoodie in size medium. However, when I opened the package, I noticed that the hoodie was not included. I have checked the entire package thoroughly, and it is clear that the item was not included or accidentally removed during the packaging process.\n\nI kindly request your assistance in resolving this issue as soon as possible. I would appreciate if the missing hoodie could be sent to me promptly or if alternative arrangements could be made. I have been a loyal customer for several years and have always been satisfied with the products and services provided by your company.\n\nPlease let me know what steps should be taken to rectify this situation. I have attached a copy of the order confirmation for your reference. If there is any additional information or documentation required, please do not hesitate to ask.\n\nThank you for your attention to this matter. I hope to receive a prompt response and a resolution to this issue.\n\nKind regards,\n\nBob."
},
{
"role": "user",
"content": "email: Hi Customer Support,\n\nQuick follow-up! I forgot to mention but it wasn't blue but more of a greenish.\n\nBob."
},
{
"role": "user",
"content": "Briefly summarize the customer's problem or question."
}
]
The response (Received chat message content) is: order no.: #123456
summary: The customer received their order but it was missing a greenish hoodie in size medium. They are requesting assistance in resolving the issue and getting the missing item sent to them promptly.
If the customer support person needs more information, they can ask a question (prompt): When did the customer receive the package?
The connector (assistant) replies (Received chat message content): The customer received the package yesterday.
Both the new question and the generated response are added to the chat history:
[
{
"role": "system",
"content": "You are a concise assistant that provides context to and answers questions about customer service tickets. These tickets consist of a number of emails. When asked for a summary, ALWAYS respond with \"order no:\" followed by the order number or \"not provided\" if not provided, and then respond with \"summary:\" followed by a one to two-sentence summary of the support ticket."
},
{
"role": "user",
"content": "email: Dear Customer Support,\n\nI am writing regarding an order that I recently placed on your website.
... (see the first code snippet for the rest of the content)
\n\nKind regards,\n\nBob"
},
{
"role": "user",
"content": "email: Hi Customer Support,\n\nQuick follow-up! I forgot to mention but it wasn't blue but more of a greenish.\n\nBob."
},
{
"role": "user",
"content": "Briefly summarize the customer's problem or question."
},
{
"role": "assistant",
"content": "order no: #123456\nsummary: The customer received their order but the blue hoodie in size medium was missing. They now mention that the hoodie is actually greenish. They are requesting assistance in resolving the issue and getting the missing item sent to them promptly."
},
{
"role": "user",
"content": "When did the customer receive the order?"
},
{
"role": "assistant",
"content": "The customer received the order yesterday."
}
]
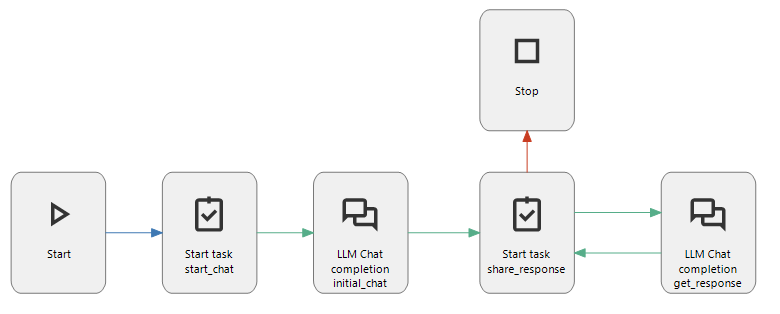 Example of LLM Chat Completion connector in a process flow
Example of LLM Chat Completion connector in a process flow
Process flow connector - LLM Completion
| Starting point Universal GUI | Starting point Windows GUI | Starting point system flow (Indicium) | System flow action |
|---|---|---|---|
| - | - | + | + |
The LLM Completion connector suggests how to complete a provided text (prompt). You can use it, for example, to complete product descriptions, draft emails, or generate code.
| Input parameters | |
|---|---|
| Prompt | The text segment to be completed by the connector. |
| Max tokens (optional) | The maximum number of tokens. The default depends on the provider and model (often 16). See also Prerequisites and limitations of LLMs. |
| Output parameters | |
|---|---|
| Output text | The received suggestion for completing the text. |
| Status code | 0 Successful -1 Unsuccessful (unknown) -2 Unsuccessful (no generative AI provider present) -3 Unsuccessful (no prompt) -4 Unsuccessful (AI model not supported for text completion) -10 Unsuccessful (no response) -11 Unsuccessful (access denied) -12 Unsuccessful (invalid request) -13 Unsuccessful (invalid response content) -14 Unsuccessful (throttling) -15 Unsuccessful (request timeout) -16 Unsuccessful (service error) -17 Unsuccessful (model not available) -18 Unsuccessful (invalid configuration) -19 Unsuccessful (function type not supported) |
| Error text | Errors from your generative AI provider. |
Example: Text completion with LLM Completion
The prompt from a user is: These P-N Junction Diodes are manufactured in Asia and can be used for
The output text from the connector could be: various electronic applications such as rectification, switching, and signal modulation. P-N junction diodes are designed to allow current flow in one direction while blocking it in the opposite direction, making them ideal for applications where controlling the flow of electricity is essential. They are widely used in power supplies, voltage regulators, LED displays, and many other electronic devices.
 Example of the LLM Completion connector in a process flow
Example of the LLM Completion connector in a process flow
Process flow connector - LLM Instruction
| Starting point Universal GUI | Starting point Windows GUI | Starting point system flow (Indicium) | System flow action |
|---|---|---|---|
| - | - | + | + |
The LLM Instruction connector can transform text following your instruction. It can, for example, summarize, translate, change the formality of, or remove sentiment from a text.
| Input parameters | |
|---|---|
| Text | The text that needs to be transformed. |
| Instruction | The instruction for the LLM how to transform the text. |
| Output parameters | |
|---|---|
| Output text | The resulting transformed text from the LLM. |
| Status code | 0 Successful -1 Unsuccessful (unknown) -2 Unsuccessful (no generative AI provider present) -3 Unsuccessful (no instruction) -4 Unsuccessful (no text) -10 Unsuccessful (no response) -11 Unsuccessful (access denied) -12 Unsuccessful (invalid request) -13 Unsuccessful (invalid response content) -14 Unsuccessful (throttling) -15 Unsuccessful (request timeout) -16 Unsuccessful (service error) -17 Unsuccessful (model not available) -18 Unsuccessful (invalid configuration) -19 Unsuccessful (function type not supported) |
| Error text | Errors from your generative AI provider. |
Example: Summarize a text with LLM Instruction
The input text is: I'm very happy to announce today that we have completed the deal. This has been in the works for over 15 months and has been quite challenging. But we did it!
The input instruction is: Reduce to only factual information, removing emotion and sentiment.
The resulting output text from the connector could be: We have completed the deal after a 15-month process.
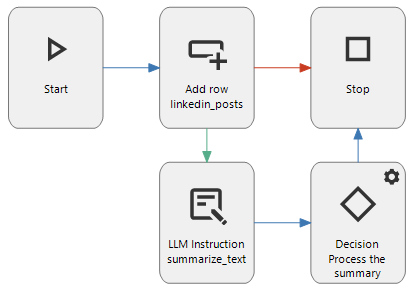 Example of the LLM Instruction connector in a process flow
Example of the LLM Instruction connector in a process flow
Process flow connector - LLM Embedding
| Starting point Universal GUI | Starting point Windows GUI | Starting point system flow (Indicium) | System flow action |
|---|---|---|---|
| - | - | + | + |
The LLM Embedding connector transforms the input text into an embedding that can be used to find semantically similar text. A solution in the Thinkstore is available to compare embeddings (see the example below).
'To embed' means to put something inside something else.
The goal of the LLM Embedding connector is to convert a hard-to-grasp object (text) into a representation that is easier to work with. Embedding refers to that conversion; it puts complex pieces of text inside a space of simpler representations.
Think of a simple graph: a two-dimensional plane with axes and an origin. You can put points on that plane and define them by two numbers: the x and y coordinates. With this representation, you can inspect:
- the distance between points (a metric for similarity)
- the angle between two points and the origin (a measure of similarity)
- arithmetic in the vector space (word-to-vec:
 , not usually seen with LLMs)
, not usually seen with LLMs)
Points on the two-dimensional plane (2D vectors) can contain only a limited amount of information. The LLM needs to store more information for the vector to represent the text well. So, it uses more numbers to represent a point in a higher dimensional space (typically hundreds to thousands of dimensions).
If a text has been transformed into a vector representation, you can calculate similarities between texts with the cosine similarity function (available in the Thinkstore). This allows you to improve text search and find the extent to which information is related. It is used, for example, by search engines to find results that are similar to the requested topic. Or you can use it to detect anomalies by setting an expected minimum threshold on the similarity between a new text and the texts in the database.
You could even use the LLM Embedding connector to embed older messages in the chat history to provide context to the LLM Chat Completion connector. This can be useful, for example, when the full context has become too large for the LLM Chat Completion connector. However, it is arguably easier to let the LLM summarize the chat history.
| Input parameters | |
|---|---|
| Text | The text that needs to be embedded. |
| Output parameters | |
|---|---|
| Embedding (JSON) | A list of numbers. |
| Status code | 0 Successful -1 Unsuccessful (unknown) -2 Unsuccessful (no generative AI provider present) -3 Unsuccessful (no text) -10 Unsuccessful (no response) -11 Unsuccessful (access denied) -12 Unsuccessful (invalid request) -13 Unsuccessful (invalid response content) -14 Unsuccessful (throttling) -15 Unsuccessful (request timeout) -16 Unsuccessful (service error) -17 Unsuccessful (model not available) -18 Unsuccessful (invalid configuration) -19 Unsuccessful (function type not supported) |
| Error text | Errors from your generative AI provider. |
Example: Find related information with LLM Embedding
The input text for a ticket is: I can't save .csv files, it gives an error and I don't know how to solve this
The resulting embedding (JSON) is:
[
-0.032498688,
-0.013597722,
0.0013119321,
-0.020781917,
... (over a thousand numbers)
-0.01832623
]
This is compared to previously calculated embeddings for other tickets. If there are tickets with the same subject (problems with saving .csv files), they most likely have a high similarity with the request and will be linked.
An implementation of the cosine similarity function is available in the Thinkstore. See Thinkstore.
select *
from meeting m
cross apply (
-- A function available in the Thinkstore for comparing embeddings
select dbo.compare_embedding(m.meeting_minutes_embedding, @question_embedding)
) n (cosine_similarity)
where n.cosine_similarity > 0
order by n.cosine_similarity desc
-- Select how much context is necessary. It should still fit the LLM prompt.
offset 0 rows fetch first 4 rows only
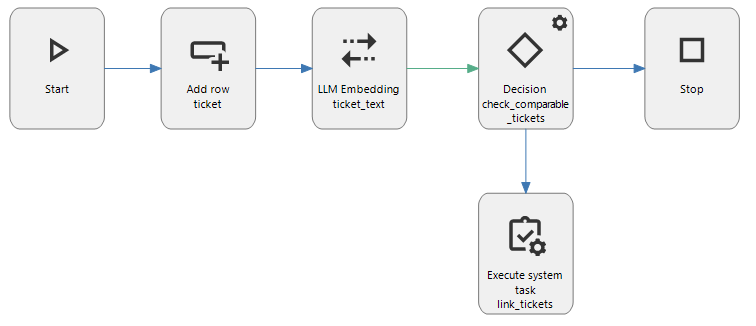 Example of the LLM Embedding connector in a process flow
Example of the LLM Embedding connector in a process flow
Example: Storing LLM embeddings with columnstore indexing
Storing LLM embeddings can benefit greatly from columnstore indexing. This can be used for various purposes, such as:
- Semantic searching within your application
- Matching similar cases
- Retrieval-augmented generation (RAG) for providing subject-related data in AI chats
Consider a system with a large number of emails with subjects and bodies. To quickly find emails relevant to specific queries, follow these steps:
- Generate an embedding for each email
- Store the embedding in a vector store
Generally, the vector store for emails would be modeled as a separate table with a clustered columnstore index:
table email_vector_store (
email_id,
vector_value_id,
vector_value
)
The LLM Embedding connector generates an embedding for each email based on its subject and body. Store the generated embedding for an individual email using the following code:
insert into email_vector_store (
email_id,
vector_value_id,
vector_value
)
select
@email_id,
cast(e.[key] as int) as vector_value_id,
cast(e.[value] as float) as vector_value
from openjson(@embedding) e
This process is performed for every email stored in the system. Once the vector store is populated with email data, it enables a semantic similarity search. For example, to find relevant emails based on a natural-language search query by the user. The search query is converted into an embedding using the LLM Embedding connector and is then processed as follows:
-- Convert the search query embedding into a temporary table
-- (refer to https://platform.openai.com/docs/guides/embeddings/which-distance-function-should-i-use)
select
cast([key] as int) as [vector_value_id],
cast([value] as float) as [vector_value]
into #search_embedding
from openjson(@search_embedding)
-- Identify the top 10 most comparable emails
select top (10)
e.email_id,
sum(v1.[vector_value] * v2.[vector_value]) as score
from email_vector_store e
join #search_embedding s
on s.vector_value_id = e.vector_value_id
order by score desc
Potential use cases for LLM connectors
These are some additional examples of functionality that you can achieve using Large Language Models:
-
Classification:
- Automatically tag tickets, products, customers, prospects, etc., based on search characteristics.
- Identify and escalate urgent customer issues by analyzing incoming communications, ensuring timely resolution.
-
Text understanding and processing:
- Use a combination of OCR (Optical Character Recognition) and Large Language Models to digitize and clean up forms, purchase orders, etc. For example, when your company still receives paper orders, you can use OCR to digitize the documents. In addition, use LLMs to clean up and parse the data so you no longer need to enter those orders by hand.
- Convert received emails into sales orders based on the email content (turn unstructured data into structured data). For example, a customer sends an email, and your application converts it into a sales order.
- Summarize content. For example, generate a management summary from 10 documents that are linked to a potential customer. This can save you a lot of time.
- Generate an explanation or information about a given object. For example: "'ESG' is an abbreviation used inside the application, what does it mean?".
- Spellcheck, translate or describe. For example, your application automatically translates an English product description to all other desired languages. Or it checks all existing descriptions for grammatical errors and recommends improvements.
-
Text creation:
- Create mock data for testing purposes to prevent GDPR issues.
- Generate creative content for advertising campaigns, maximizing engagement and conversion rates.
- Generate a web shop description for products based on their properties.
-
Content validation:
- Automate compliance checks (check if input adheres to a set of rules).
For example, if a ticket regarding an error does not contain an error log, generate an automated reply asking for the error log.
- Check whether a reply meets business standards. For example, check whether an employee's response to a customer adheres to internal standards regarding tone, sentiment, etc.
- Automate compliance checks (check if input adheres to a set of rules).
For example, if a ticket regarding an error does not contain an error log, generate an automated reply asking for the error log.
-
Recommendation:
- Suggest a product based on a description by the user (smarter natural language-based search). For example, a search box in which an employee can type natural text (like "a size 9 red shoe"), and the application returns corresponding products. Or make your application recommend similar products if a product is out of stock.
-
Answering questions:
- Answer questions a user asks about data in your business application. For example, "How many products have we sold today? or "Which employee best fits a project?".
- Thinkwise Academy - Artificial Intelligence (Associate)
- Thinkwise Academy - AI & Model Enrichments (Expert)
- Community post - Connect to your preferred generative AI model
Generative AI troubleshooting
AI connector error
Full message: "AI CONNECTOR ERROR. The request was invalid. Check your provided input."
This error can occur when you are using an unpaid version of a generative AI provider.
To fix this error:
- Use a paid version of a generative AI provider. For more information, see Prerequisites and limitations of LLMs.
- Configure the paid version of the generative AI provider in the Software Factory. For more information, see Set up a generative AI provider for a branch.