2023.1
Support for this release has ended. The release notes are still available for reference, however, no additional updates will be provided. Update to the latest version. See our Lifecycle policy for more information.
We are very excited to announce version 2023.1 of the Thinkwise Platform.
This release contains a major change in version control that affects a large part of the Software Factory. Make sure you carefully read all release notes for this change, as mentioned under the topics Breaking and A new way of version control.
Contents
- Contents
- Upgrade notes
- Breaking
- A new way of version control
- Introduction
- A visual representation
- 'Project' and 'project version' now 'model' and 'branch'
- Branches and model versions (point in time)
- Models - Merge sessions
- Models - Export and import
- Ribbon
- Creation
- Synchronization to IAM
- Deployment package
- 'Data conversion' now 'Data migration'
- Functionality
- Code review
- Validations
- Quality dashboard
- Work overview
- Function point analysis
- Historic information
- Software Factory - New and changed
- Models - Export and import changed
- Models - Multiple live versions
- Data - Domain input constraints
- Process flows - Column 'API' renamed
- Process flows - Labels in the Output tab
- Process flows - Custom schedules disabled if no longer allowed
- Process flows - OAuth connectors
- Process flows - New action 'Open link'
- Process flows - New action 'Merge PDF'
- Process flows - New action 'Close all documents'
- Process flows - New authentication type for HTTP connector
- User interface - Separate tab for combined filters
- User interface - Set the component for a conditional layout
- User interface - Icon repository
- User interface - Exported theme file downloaded
- User interface - Custom look-up display column for Maps
- File storage - Azure Blob Storage support
- File storage - Azure files SAS token support
- File storage - 'Storage' instead of 'disk'
- Business logic/Processes/Data - Select objects to include in copy tasks
- Business logic - Abandon control procedure
- Business logic - Code search for inactive control procedures
- Business logic - Obtain the original login user
- Quality - Smoke tests
- Quality - Delete a test run
- Quality - Usability unit tests improved
- Quality - Undo the (dis)approval of a control procedure
- Quality - Validations
- Access control - Tags for roles screen
- Deployment - Source code generation
- Deployment - Pool user credentials
- Deployment - New procedure for automation
- Maintenance - Automatic removal of job information
- Software Factory - Fixed
- Creation - Job successful after creating a database
- Creation - Database creation for non-default runtime configurations
- Creation - Merging base models into work model
- Creation - System flow for notification e-mail
- Deployment - Write deployment manifest follow up
- Inconsistent line endings in code
- Process flows - Hidden columns in process actions
- Process flows - Program object for process action without a next step
- Foreign key index creation on composite primary keys
- Data - Delete undesired objects in data migration
- Quality - Unit testing objects with @error_msg parameter
- Intelligent Application Manager - New and changed
- Intelligent Application Manager - Fixed
- Data model changes
Upgrade notes
Recommendations
For this upgrade, we recommend the following:
- Available space: 1,5 times your current database size (1,5 * database).
- Run a shrink database action after the upgrade since quite some space will be available.
This is a big release, and especially for large databases, running the script 4999_squash_history.sql may take a long time to run
(it squashes the historical data).
If the upgrade takes too long, you can remove it from the folder \Upgrade\2023.1 in the deployment package.
At a later moment, during development downtime, you can run it manually in SQL Server Management Studio.
It can be run multiple times. If removed, the initial upgrade will still be successful.
SQL Server and .NET Framework support
-
The Software Factory development environment and the Intelligent Application Manager require SQL Server 2017 or higher.
Read about the end of SQL Server 2016 support here: https://community.thinkwisesoftware.com/news-updates-21/end-of-sql-server-2016-support-2344
-
This also applies to the Windows and Web user interfaces, which additionally need version 4.7 minimum of the .NET Framework (4.7.2 is advised for Web).
-
The Indicium application tier requires SQL Server and .NET 6.0. Indicium Basic requires .NET Framework 4.7.2. For more information please check the Indicium documentation.
Re-generate model definition
After every platform upgrade, always re-generate the definition of your work model before you start developing it (menu Deployment > Creation > tab Generate definition). This applies changes in the base models to your work model.
Note: if you are using nested base models, re-generate all base models below the highest level before you re-generate the work models.
Breaking
'Project' and 'project version' renamed
During the upgrade of the Software Factory to version 2023.1, all occurrences of 'project' and 'project version' will be renamed to 'model' and 'branch'. This includes phrases such as 'project', 'project_vrs', '@project_id', '@project_vrs_id' and 'base_project_id'. The upgrade could break existing dynamic code, control procedure code, and validation code as it replaces all occurrences it can find.
Please double-check and validate that all code has been converted correctly.
For more information, see A new way of version control.
Scheduler formalized
new Universal GUITo extend the configuration of the Scheduler component in the Universal GUI, we have made the scheduler a formal part of the Software Factory. It is available in the menu User interface > Schedulers.
The Schedulers screen allows more settings for customizing the different scheduler views. In the future, this enables setting up custom timescales.
At the moment, only the previous (heuristic) timescales will be available and can be configured limitedly.
So, the Universal GUI will no longer heuristically configure schedulers but rely on the configured schedulers in the model instead.
As a result, unauthorized columns included in the heuristic approach of the Universal GUI are not allowed in the formalized schedulers. For instance, when a multi-line column was unauthorized in a 2022.2 environment, the Universal GUI would pick the next available multi-line column as the tooltip column. This could result in users with different rights having different tooltip columns in the scheduler. The formalized scheduler will use the first multi-line column as the tooltip column, regardless of its authorization. This rule applies to tooltips, start- and end dates, and grouping columns.
Formalization of the scheduler has also made the extended property SchedulerPeriodInYears obsolete.
This property would set the number of years to look ahead from the current date for an application or runtime configuration.
During the upgrade, each model's first setting of this property will be used.
During the 2023.1 upgrade, all subjects using a Scheduler screen type component and heuristic visualization requirements will automatically be upgraded to a configured scheduler. Verify that your schedulers are configured as intended.
New validations for the scheduler:
- Default scheduler view has show disabled
- Default scheduler view on scheduler variant has show disabled
- Scheduler uses a column that is not suitable as activity end date column
- Scheduler uses a column that is not suitable as activity start date column
- Scheduler uses a column that is not suitable as activity title column
- Scheduler uses a column that is not suitable as activity tooltip column
- Scheduler view interval does not fit the parent time scale.
Creation - Using dbo.tsf_user() as default value query
FixedWhen the function dbo.tsf_user() was used as a default value query, it could not be dropped during the Full generation process because it was in use by the table as default value. This has been fixed.
Now, both the tsf_user and the new tsf_original_login functions have proxy functions that will be used when dbo.tsf_user() or dbo.tsf_original_login()
are used as a column's default value query.
This allows recreating both tsf_user and tsf_original_login.
Therefore, it is possible to upgrade using both the Full and Smart generation methods.
When upgrading to 2023.1, upgrade validation messages will be created for each column using either dbo.tsf_user() or its content as the default value query.
The message will explain that columns can now safely use dbo.tsf_user() as the default value query.
Make sure that tables with columns using dbo.tsf_user() or dbo.tsf_original_login() are set to be rebuilt.
This ensures the column's default value will use the corresponding new proxy function.
A new way of version control
Introduction
Up to the 2022.2 release, version control in the Software Factory was handled by creating a copy of an entire model as a project version. This had a major drawback: since changes make up only a minor percentage of the entire model, all the other unnecessarily copied data made the Software Factory databases grow over time and become slower due to their size.
To solve this problem, we will handle version control from now on by using temporal tables. These tables, also known as system-versioned tables, are a database feature that brings built-in support for providing historical data. It means that only the latest version of every project will be stored, and all old data will be moved to history tables. This way, data modifications will be stored only once. The historical data can be accessed whenever required by requesting them for a specific time in the past.
For more detailed information about temporal tables, please consult the Microsoft documentation.
The use of temporal tables offers great benefits:
- The main benefit is performance improvement by separating the operational data in the Software Factory from the non-operational data. Less operational data needs to be called upon when, for example, copying a project or branching/merging.
- It is no longer needed to store massive amounts of unnecessary data.
- Less risk that a developer accidentally modifies an earlier version of the model because they will always be working in the most recent version.
A visual representation
In the image below, the circles represent data in the Software Factory database. The grey background represents the historical data, and the green background the operational data.
The top half shows the situation preceding the 2023.1 release. You can see that the branch circle grows exponentially, depending on the number of versions in the branch. For example, branch A is larger than branch B because it contains four versions instead of two. The same can be said about the project versions.
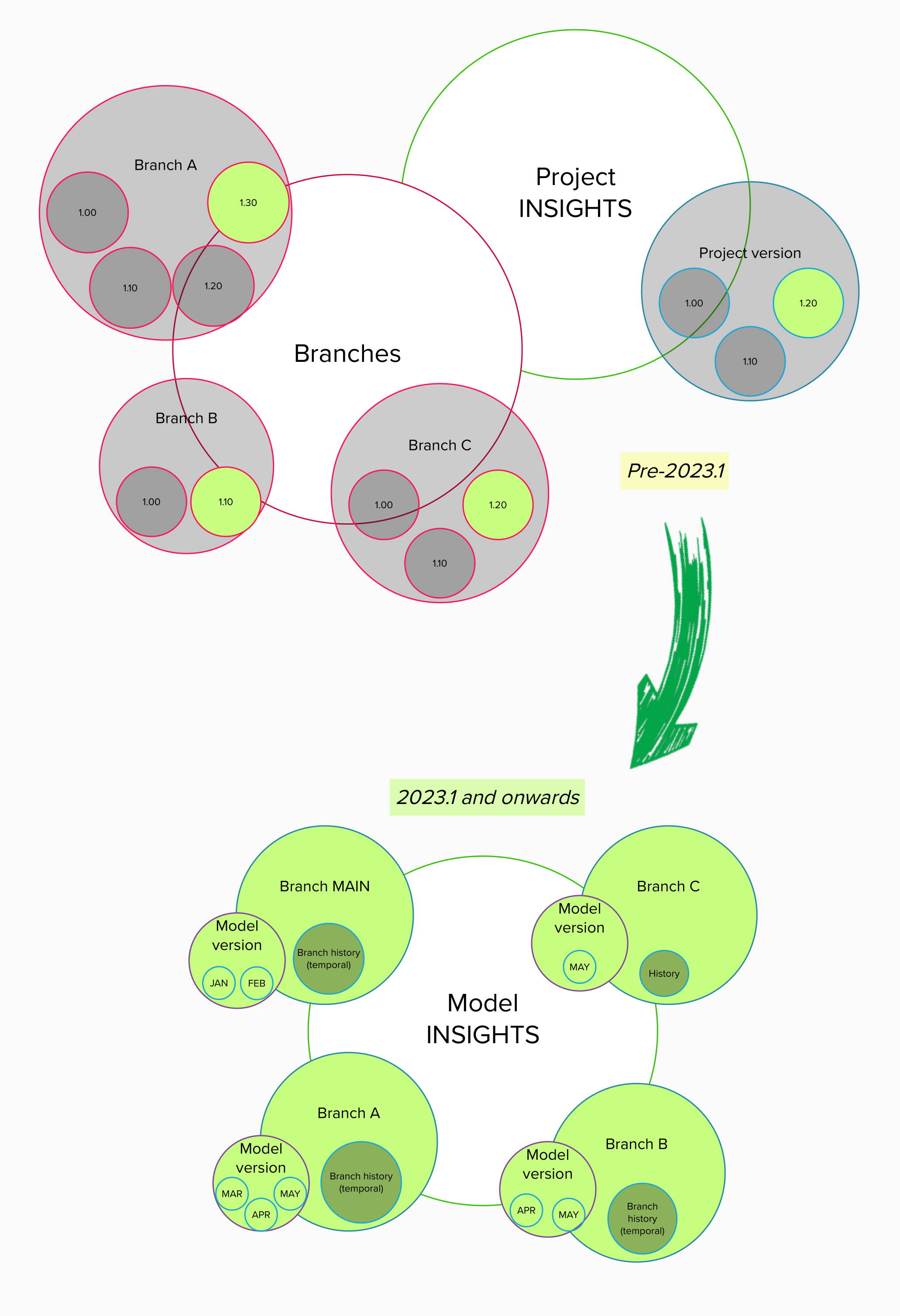 A visual representation of the transition to temporal tables
A visual representation of the transition to temporal tables
The bottom half of the image shows the situation for the 2023.1 release and onward. A branch may contain multiple model versions, with the latest version being the current version. So, all four branches are a similar size regardless of the amount of model data they contain. They will not even noticeably grow in size when they contain multiple model versions since only one point in time is saved to build the model at that point.
Only the history tables can grow in size. The history tables in branches MAIN and A are larger than those in B and C because more changes have been executed and stored. However, because the history tables are called only in very specific processes, this does not impede the performance of the Software Factory.
'Project' and 'project version' now 'model' and 'branch'
In the Software Factory, a project used to be similar to a model. However, outside the Software Factory, a project can be much more than just the application or part of an application being built.
Since the Thinkwise platform is based on model-driven software development, we have decided to replace the term Project with Model. For example, the menu item Project overview is now called Model overview. To prevent confusion due to this change, menu item Full model has been renamed to Model content. This better covers the core of the Software Factory and prevents confusion about how the word 'project' is used in daily life.
During the upgrade to platform version 2023.1, all projects will be converted to models:
- In this process, the main project version will become its own branch.
- Old project versions will become temporal data. This means that all historical data from previous project versions will be migrated to the history tables in the correct order. This way, a timeline of all the history is created within the context of one MAIN branch. After the migration, the most recent project version will become the active model branch.
- Because of this, old base project versions can no longer be linked easily to their work models. Therefore, the upgrade software will detect old base project versions that are in use and create branch projects for them. These branch projects will be converted to branches and linked automatically to the correct work model.
- Old branches were previously considered as projects with versions. During the 2023.1 upgrade, they will be moved to the model they originally branched from.
- For occurences in code, see Breaking - Project and project version renamed.
 'Models' instead of 'Projects'
'Models' instead of 'Projects'
Branches and model versions (point in time)
Implementation of temporal tables means it is no longer required to copy all model data into a new project version to save a specific point in time. This means that project versions as we used to know will cease to exist in the 2023.1 release.
However, we still want to use branching and merging as we know them.
Therefore, instead of project versions, we will start using branches. These are versions of the same model that can differ from each other. Every model will have at least a MAIN branch and can contain one or more additional branches based on a specific point in time in the past.
Within a branch, you can mark the situation at any point in time (except for the future) as a model version. This is similar to the branching model used in GIT, where branches are effectively a pointer to a snapshot of your changes.
When necessary, you can compare two model versions, for example, between two branches or two points of time within one branch. It is also possible to mark a model version with a name for easy communication.
It is not possible to rename a model or branch because that would cause a loss of history.
When you create a new model, the Software Factory will automatically add the MAIN branch. If it is a new work model, the Software Factory will automatically link default base models to it. Only branches without origin or default base models will be linked to the new work model.
Upon creating a new model or branch, it is possible to switch to the new model or branch. This prevents working in the wrong branch.
- If you choose to switch, all open documents will be closed, and your session will be updated to the new model or branch. The Model overview screen will be reopened automatically with the new model/branch combination as the selected row.
- If you do not switch, the Software Factory keeps all documents open in the context of the original model/branch combination. In addition, a new Model overview screen is opened with the new model/branch combination as the selected row.
Tasks are available to add ![]() and remove
and remove ![]() models and branches that need to be available in the prefilters My models and My branches
models and branches that need to be available in the prefilters My models and My branches ![]() .
An overview of all the models and branches that are shown or hidden with these prefilters can be found in the menu Maintenance > Users > tab Runtime configurations.
.
An overview of all the models and branches that are shown or hidden with these prefilters can be found in the menu Maintenance > Users > tab Runtime configurations.
If only one branch has been marked to be shown in the prefilters, it will be selected automatically when you start the Software Factory. In all other cases when you start the Software Factory, you need to select or confirm the model and branch in a pop-up. The most recent branch you worked in will be selected by default.
As for the status, branches can now only be either active or inactive. A dedicated status field is no longer necessary since we are now upgrading from one point in time to another. So, the same branch can be in development at 11 AM and in test at 5 PM.
 A branch can be active or inactive
A branch can be active or inactive
Model versions can have only one of the following statuses: test, acceptance, or production. An active branch is always in development, so that model status has become redundant.
 A model version can have the status test, acceptance, or production
A model version can have the status test, acceptance, or production
Models - Merge sessions
In the new situation, branching and merging consist of the following steps:
-
When you create a new branch
 (menu Models > Model overview > tab Models):
(menu Models > Model overview > tab Models):-
It is no longer a stand-alone project branch but a branch within the model. You can base it on the current point in time, a specific point in time, or select a specific model version.
-
The origin is tagged with the current point in time.
-
The branch is copied from that point in time.
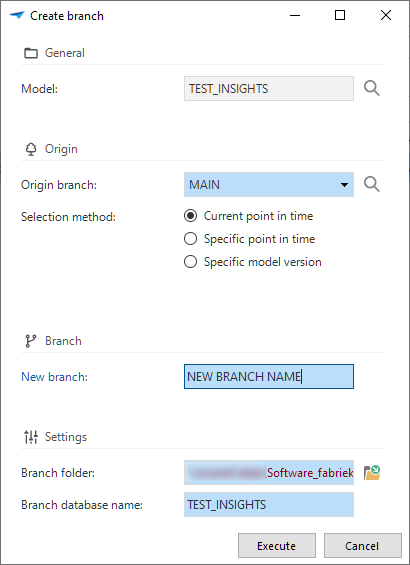 A branch created within the model
A branch created within the model
-
-
When you create a merge session
 (menu Models > Merging > tab Merging):
(menu Models > Merging > tab Merging):- Changes are determined by comparing the situation at the origin point in time vs. the current point in time (i.e., the moment when the merge session started).
-
When you execute the merge session
 (menu Models > Merging > tab Merging):
(menu Models > Merging > tab Merging):-
Only changes from either the source or the origin are executed.
-
By default, the branch that is merged into another branch will be deactivated after the merge. If you wish to continue working in that branch, you should uncheck the Deactivate branch box.
 Branch is deactivated after the merge is executed
Branch is deactivated after the merge is executed
-
Previously, the project version would be copied three times during a cycle of branching and merging. From now on, the branch (previously: project version) will be copied only once.
Because of the transition to temporal tables, the merge sessions executed before the upgrade to the 2023.1 release will be migrated. This migration has been included in the upgrade script for the 2023.1 release to ensure that all existing merge sessions remain connected to their model and branch.
In the merging process (menu Models > Merging), conflicts no longer arise between a trunk and a branch but between an origin and a branch of the origin. The origin is always on the left, and the branch on the right.
To resolve a conflict, there are now two situations:
-
An entity has been inserted in both the origin and the branch. You can choose not only what to do with the conflict actions but also with the dependent actions.
Resolution Description - Carry out the branch action, including dependent origin actions
- Carry out the origin action, including dependent branch actionsCarries out dependent actions and results in (new) conflicts if they are conflicted. - Only carry out branch actions
- Only carry out origin actionsOnly applies the dependent action of the selected branch but not the dependent actions of the other branch. -
An entity has been deleted or updated in both the origin and the branch, or deleted in one and updated in the other branch. For these types of conflicts:
Resolution Description - Only carry out the branch action
- Only carry out the origin actionChoose what to do with the conflict action (not the dependent action). For example, when the delete action of a table is chosen, the table is no longer available, so column insert or update actions cannot be executed.
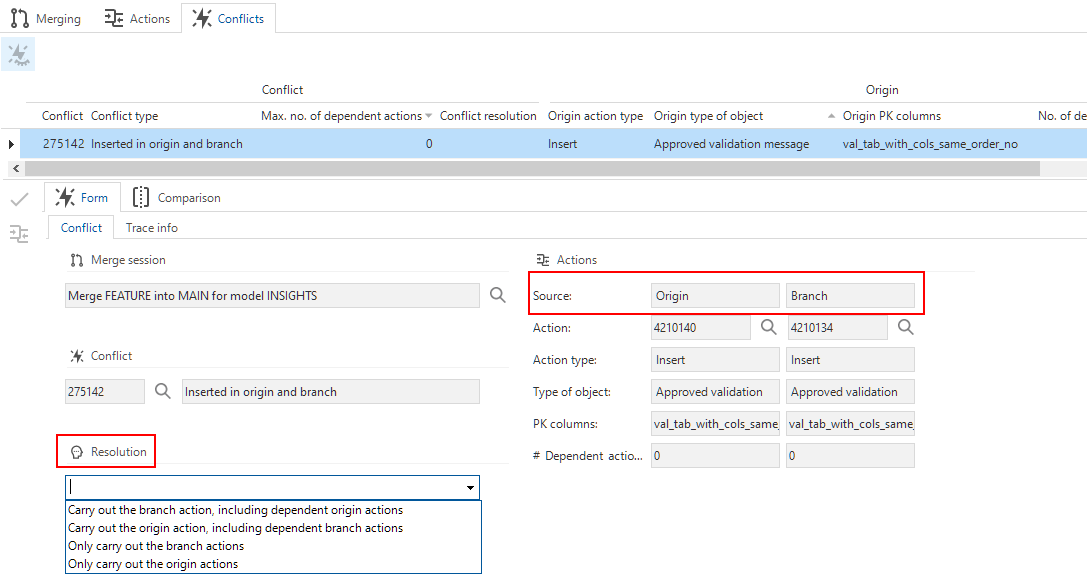 Conflict resolution between origin and branch
Conflict resolution between origin and branch
When executing a merge session, two model versions will be created in the target branch to indicate the moments before and after the merge session. This allows you to easily revert a branch to undo a merge session.
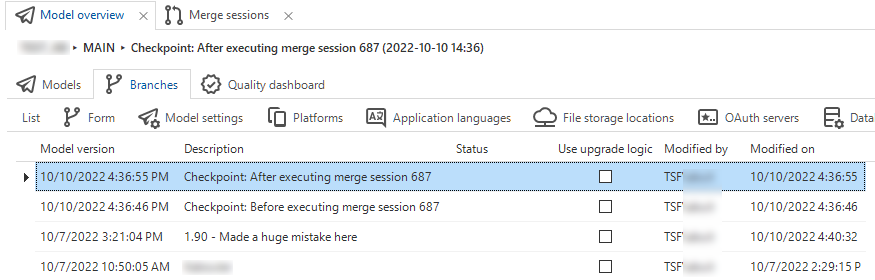 The moments before and after the merge session
The moments before and after the merge session
Undoing a merge session is still possible. However, the Undo merge session functionality in earlier versions of the Software Factory, has been replaced by the possibility to revert a branch.
Undo merge session used to 'rewrite history'. Now, reverting a branch to an earlier point in time will simply undo any changes done to the model.
The task to initiate this action is called Revert branch ![]() .
It is available in the menu Models > Model overview > tab Branches > tab List and tab Model versions.
You can use this task to revert a branch in two situations:
.
It is available in the menu Models > Model overview > tab Branches > tab List and tab Model versions.
You can use this task to revert a branch in two situations:
- After a merge session, if the result is undesired.
- Without a merge session, if something went wrong in a branch and you want to make a fresh start.
You can either revert the branch immediately or review the changes that will occur when reverting the branch.
Reviewing the changes will take you to a merge session that shows all the actions that will be taken as if the reversal was initiated in a branch. This type of one-sided merge session will never have conflicts. Execute the merge session to finish the reversal.
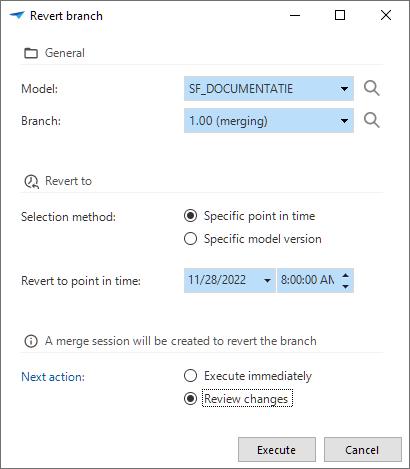 'Revert branch' replaces 'Undo merge session'
'Revert branch' replaces 'Undo merge session'
Models - Export and import
From now on, exporting and importing is always executed at the model level. This prevents importing branches into unrelated models.
You can export a specific model and branch combination by executing the Export model ![]() task.
The created export file can be imported into another model or even another Software Factory.
task.
The created export file can be imported into another model or even another Software Factory.
It is only possible to import ![]() a model into a model without a branch or into a new model that does not yet exist.
a model into a model without a branch or into a new model that does not yet exist.
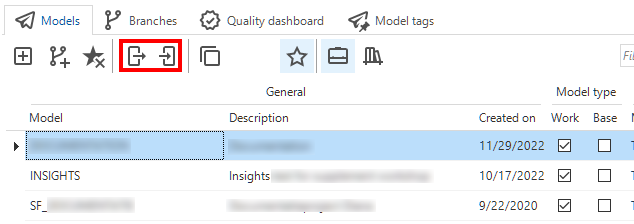 Export and import models
Export and import models
Ribbon
In the Software Factory's ribbon, the tab Project has been removed. Instead, when you start the Software Factory and multiple work models are available, you can select your Model and Branch in a popup. If only one work model is available, it will be selected automatically.
To work in another branch, you can use the menu item Switch branch in the Models menu. If you switch to another branch, either this way or by creating a new model or branch, all open documents in the Software Factory will be closed to prevent working in the wrong model or branch.
In addition, the buttons to open Thinkwise platform documentation and the Community have been moved to the Developer tab. They are now visible for every application opened in developer mode.
 Switch branch, Documentation and Community in the Developer tab
Switch branch, Documentation and Community in the Developer tab
Creation
In the Creation process (menu Deployment > Creation), some steps have changed due to the change to temporal tables.
In step Generate definition, your branch is now marked as a moment in time (in model_vrs) when it is generated.
When you execute all or several steps ![]() in the Creation process at once,
you can assign a name to the model version.
in the Creation process at once,
you can assign a name to the model version.
When starting ![]() the definition generation, you can select your source for data migration and upgrade.
This can be done by obtaining it from the database or by selecting a specific model version.
In the same task, you can choose to continue the generation (default) or to go to the Data migration screen to review the mapping.
the definition generation, you can select your source for data migration and upgrade.
This can be done by obtaining it from the database or by selecting a specific model version.
In the same task, you can choose to continue the generation (default) or to go to the Data migration screen to review the mapping.
The source branch and model version for the data migration and upgrade, as set during the definition generation, is also visible in the menu Models > Model overview > Branches > Form.
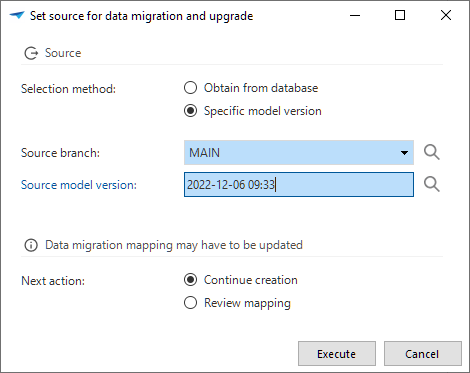 Set the source for the data migration and upgrade
Set the source for the data migration and upgrade
In step Execute source code, the model version is recorded in the sf_model_info table
and thus used for creating and upgrading code files (creating and upgrading databases).
To enable this, the base model SQLSERVER_MODEL_INFO will be linked to every work model during the upgrade to version 2023.1. Do not unlink this base model.
After successfully creating or upgrading a database, the fields for the source branch and model version for the data migration and upgrade are updated. In this way, it will match the model version on which the source code was based.
After the update, an entry will be added to the execute source code log (menu Creation > tab Execute source code > tab SQL output). Note that the model version time is in UTC time.
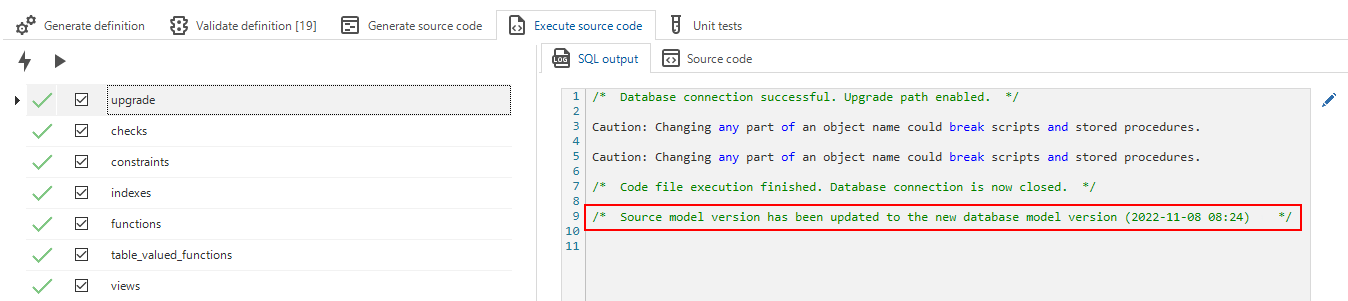 The source branch and model version have been updated after executing the source code
The source branch and model version have been updated after executing the source code
Synchronization to IAM
You can now synchronize to IAM or storage with a different model name and branch name. This allows you to release your product with its own name and release number. For example, your model in the Software Factory is called 'ERP', but you can release it as 'Thinkwise Software' version '2.3' by assigning a different model (Thinkwise Software) and branch (2.3) name.
Both Synchronize to IAM ![]() and Synchronize to storage
and Synchronize to storage
![]() (menu Deployment > Synchronization to IAM) support these options.
(menu Deployment > Synchronization to IAM) support these options.
To synchronize an older model version, you first need to create a branch from that particular moment in time and then synchronize that branch.
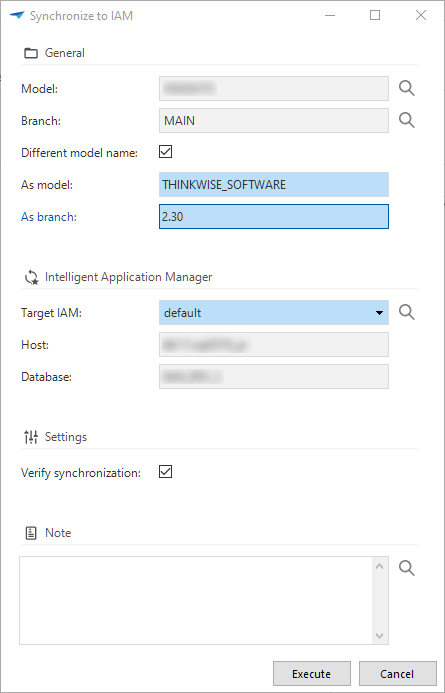 Synchronize to IAM with a different model and branch name
Synchronize to IAM with a different model and branch name
Deployment package
When creating a deployment package (menu Deployment > Deployment package), it is now mandatory to specify a Model version name. This name will be stored in the menu Models > Model overview > tab Branches > tab Model settings.
Optionally, you can use a different model name.
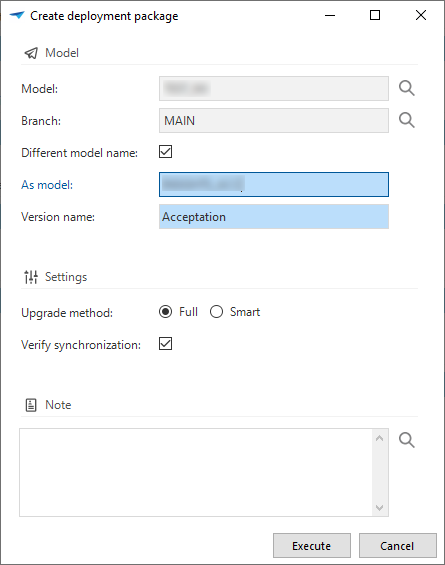 Changed model, branch, and version name in a deployment package
Changed model, branch, and version name in a deployment package
'Data conversion' now 'Data migration'
Before the switch to temporal tables, a project's version control was based on comparing two project versions. Now, you can compare two branches or two points in time within one branch based on the temporal history. Model versions are set in the definition generation process.
If you obtain the latest model version of your end-product, the branch's source branch and model version will be set to that version. This allows easy generation of upgrade scripts for different end-products.
This change has led to a major overhaul of the look, feel, and usability of the Data migration screen (previously: menu Data > Data conversion):
-
Data conversion has been renamed to Data migration because this better describes the screen's content. Of course, the menu item also has been renamed: menu Data > Data migration.
-
You can now easily set the source
 for data migration and upgrade by obtaining it from the database
or manual selection. To prevent problems, this is not possible when jobs for definition generation or validation, or for source code generation are queued or active.
for data migration and upgrade by obtaining it from the database
or manual selection. To prevent problems, this is not possible when jobs for definition generation or validation, or for source code generation are queued or active.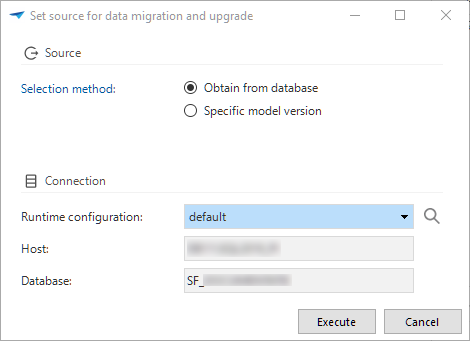 Set the source for data migration and update
Set the source for data migration and update -
When you set the source to an earlier version (for example, when releasing a major version), all mapping for the development versions in between will not be included by default. In that case, you can re-apply intermediate mappings
 that have an earlier configured source
or a different branch further down the origin chain.
The task shows which intermediate versions contain mapping information that could be applied.
When you execute the task, these mappings will be applied recursively.
Mappings configured directly to the target branch will be favored over mappings between a source branch and other intermediate versions in this source branch.
that have an earlier configured source
or a different branch further down the origin chain.
The task shows which intermediate versions contain mapping information that could be applied.
When you execute the task, these mappings will be applied recursively.
Mappings configured directly to the target branch will be favored over mappings between a source branch and other intermediate versions in this source branch.
After re-applying intermediate mappings, always verify the results.
 Re-apply intermediate mappings
Re-apply intermediate mappings
- Data used to be edited in the grid or form, which was not the most intuitive way to set up data migration.
Therefore we have disabled the editing in grid and most of the form, and implemented tasks instead:
- Tasks in tab Tables:
 Update table mapping: specify the from and to table, thus mapping two tables against each other.
Update table mapping: specify the from and to table, thus mapping two tables against each other. Disconnect table mapping: reset the mapping of two tables,
thus splitting one record with a from and to table into two records, one with a from and one with a to table.
Disconnect table mapping: reset the mapping of two tables,
thus splitting one record with a from and to table into two records, one with a from and one with a to table. Rebuild table: forced rebuild of a table, even if it has not been changed according to the comparison.
Rebuild table: forced rebuild of a table, even if it has not been changed according to the comparison. Fully reset data migration: reset the data migration to its original starting point.
Fully reset data migration: reset the data migration to its original starting point. Reset table mapping: reset the table to its original starting point.
This is only possible when the table mapping has been updated manually (the generated checkbox is cleared).
Reset table mapping: reset the table to its original starting point.
This is only possible when the table mapping has been updated manually (the generated checkbox is cleared).
- Tasks in tabs Columns and All columns:
- Update column mapping: specify the from column, to column, and default value or expression.
Depending on the selected values, some options will become mandatory or unavailable.
- Disconnect column mapping: reset the mapping of two columns,
thus splitting one record with a from and to column into two records: one with a from and one with a to column.
- Reset column mapping: reset the column to its original starting point.
This is only possible when the column mapping has been updated manually (the generated checkbox is cleared).
- Tasks in tab Tables:
- Most forms have been removed to improve usability by providing more space for the data in the grid. Only the default value and expression in the column mapping are still visible in the form.
Functionality
Control procedures and templates used to have history tables to save every code change. These changes were visible in tab Code changelog (menu Business logic > Functionality). Due to the introduction of temporal tables, these processes have become redundant, so refactoring the changelog was necessary. To store and safeguard changes, we have changed some tabs and processes.
Changed tabs:
- Tab Code changelog has been removed.
- Tab Code review has been added. It contains three other tabs:
- Code review - an overview of all changed control procedures, also when they are still in development.
- Changes - an overview of every change since the last time a control procedure has been completed. Here you can see which templates are new, updated, or deleted. Previously, this was only possible if a control procedure was in review.
- Comments - an overview of all comments on every change in the selected code review record. For more information, see Code review.
Changed processes:
- When a control procedure is marked as Ready for review, the code will no longer be saved in the changelog but handled by the temporal tables.
The review will be based on the live code of the control procedure. All changes are visible in tab Code review.
Note: since a control procedure is now limited to a single source that represents its review status, a merge conflict may arise when it is set to review in both branch and origin. You can select only one to be merged. - Upon approval, a snapshot of the control procedure and template is logged for historical purposes.
- Upon disapproval, the status is set to Waiting for developer. The prefilter and icons match this status. The tooltip will indicate whether your input or the input of another developer is required.
- When undoing the approval or disapproval, snapshots of code for the selected change log record are erased, and the control procedure status reset to Review. This way, the live code will be available again for review.
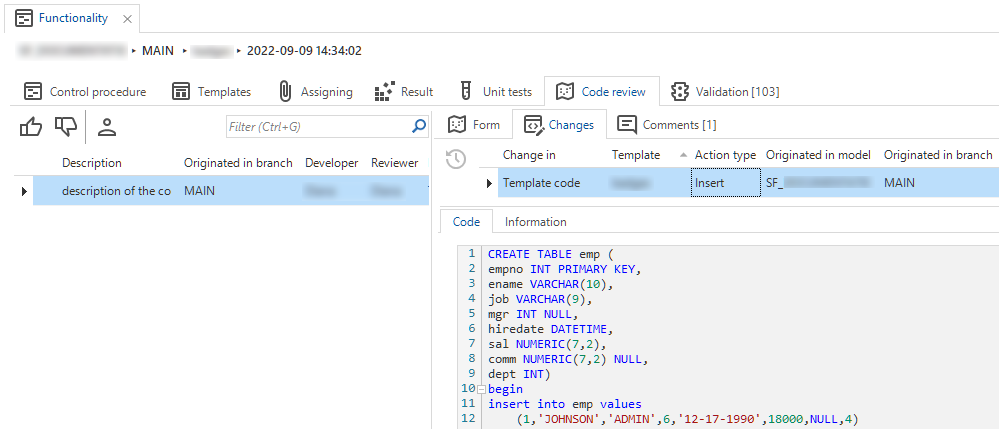 Changelog has been replaced by Code review > Changes
Changelog has been replaced by Code review > Changes
Not only some tabs and processes in Functionality have been changed. We have also revised the naming of program objects for weaving code in the upgrade code file. From now on, the program object names in the menu Business logic > Functionality > tab Assigning will state the from model version.
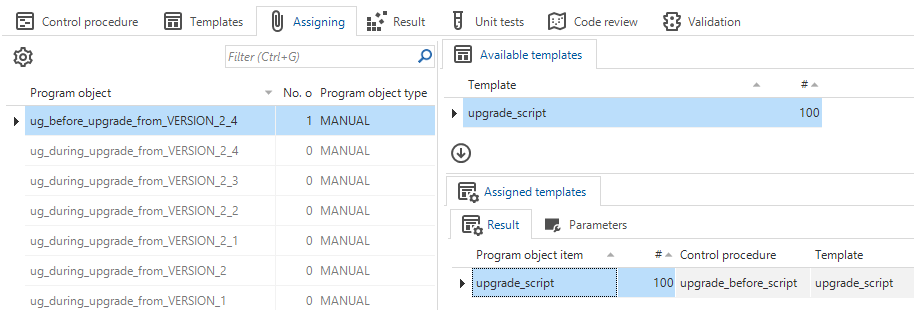 Names for program objects changed
Names for program objects changed
This change requires the model version to have a Description that should be entered in the menu Models > Model overview > Branches > Model versions. In the same screen, if no version specific program objects are available, you should mark the model version to use upgrade logic by selecting the checkbox Use upgrade logic. To keep the list of upgrade program objects manageable, clear this option for older model versions.
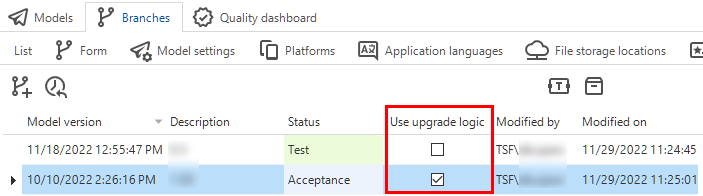 Mark a model version for use in the upgrade logic in the Model overview
Mark a model version for use in the upgrade logic in the Model overview
Code review
The switch to temporal tables has also led to a changed and improved commenting process in the Code review screen (menu Quality > Code review).
In the Changes tab, it is now possible to add a comment to a specific change. This allows a reviewer to comment on a specific change and makes it more clear to developers which comment is about which change. New comments are linked automatically to the selected change.
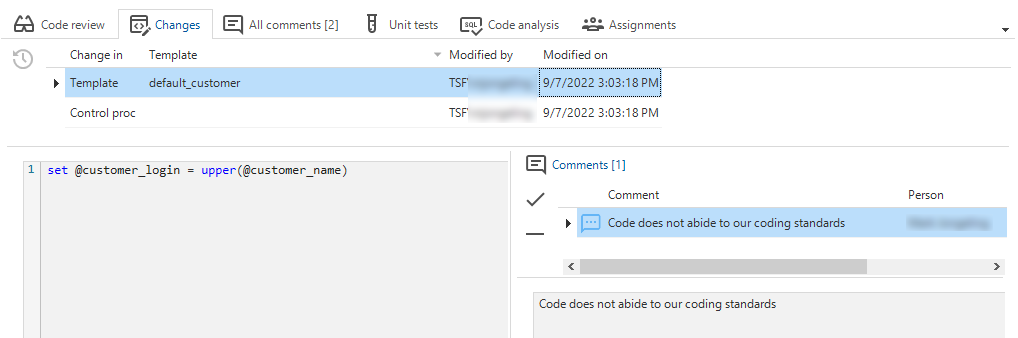 Add a comment to a change
Add a comment to a change
The Code review screen also contains a new tab: All comments. It contains an overview of all the comments on every change in the selected code review record. Leaving a comment in this overview does not need to be linked to a change.
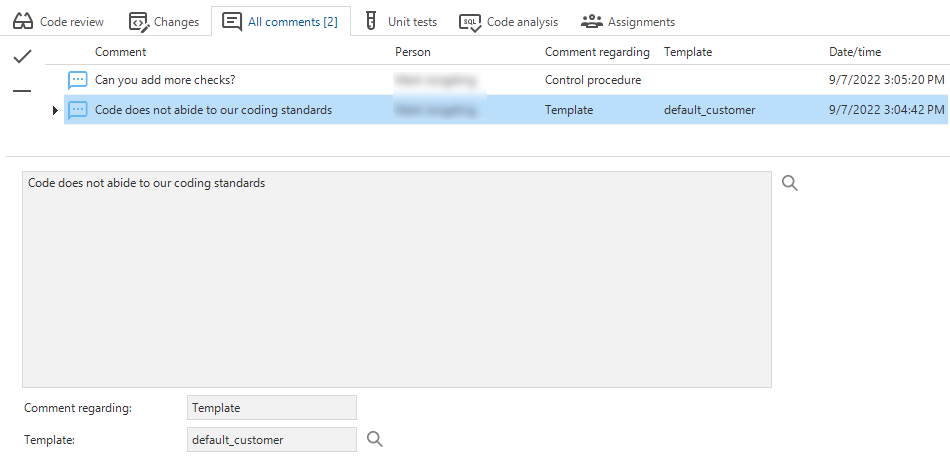 An overview of all comments
An overview of all comments
The automatically generated comments state whether a control procedure has been disapproved or retracted. The following situations and comments are possible:
- Changes to the control procedure's code after it has been marked for review:
- Title: "Control procedure was updated after it was submitted for review."
- Comment: "The control procedure was updated by [Developer] after the changelog was submitted for review."
- Changes to the template code after a control procedure has been marked for review:
- Title: "Template was updated after it was submitted for review."
- Comment: "The template code was updated by [Developer] after the changelog was submitted for review."
- Changes to the status of the changelog or code review:
- "Code review was retracted by [Developer]."
- "Code review was disapproved by [Developer]."
- "Code review has been reopened by [Developer]."
Validations
Since project versions have become obsolete, we have removed the option to approve messages temporarily until the project version is copied (menu Quality > Validations).
Instead, we have introduced the option to approve a message until a specific point in time in task Approve validation message temporarily ![]() .
The message will reappear the first time a validation is executed after this time has passed.
.
The message will reappear the first time a validation is executed after this time has passed.
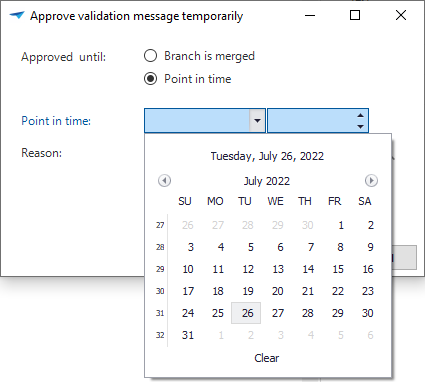 Task to temporarily approve a validation message
Task to temporarily approve a validation message
In addition, historical approvals are now visible in a new tab. This visualizes why a validation message "suddenly" reappears in the validation overview.
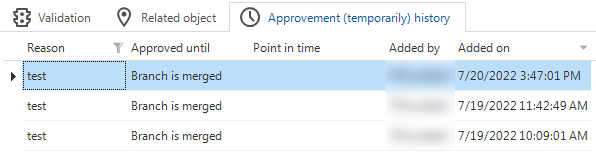 New tab with the history of temporarily approved validations
New tab with the history of temporarily approved validations
It is still possible to temporarily approve a validation until the branch is merged. Which one you choose depends on the situation:
- Approved until the branch is merged - select if the message should be solved after the next merge, regardless of the point in time.
- Approved until a point in time - select if it does not matter in which version the message needs to be solved.
Quality dashboard
Previously, the Quality dashboard would show data for all projects and project versions. Due to the transition to models and branches, it now only shows the data for a specific branch:
- When you open the dashboard from the menu (menu Quality > Dashboard), this will be the branch you are currently working in.
- When you open the dashboard from the Model overview (menu Model > Model overview > tab Quality dashboard), this will be the branch you selected in tab Models.
This change has significantly increased the dashboard's performance.
In addition, to help you and your team improve branch quality, the dashboard now opens automatically after you start the Software Factory and select a model and branch, but only if the selected model is a work model. This provides daily insight into the quality level of the branch in which you are working. If you change the model by using the Switch branch task, the dashboard will not open automatically.
This behavior of automatically opening the dashboard can be changed with a configuration setting in menu Maintenance > Configuration > tab Configuration > checkbox Start with Quality dashboard.
Work overview
When designing and writing requirements, you can create work items to log what work needs to be done to fulfill a specific feature.
This work can be now linked to a planned (future) model or branch with the refactored Create model or branch task ![]() .
.
This task is available in the menu Specification > Work overview for work items for which the task has not yet been run. Each work item that is selected when you create the model or branch will be linked to it.
This task replaces the previous task that created a project, a copy of a project, or a branch.
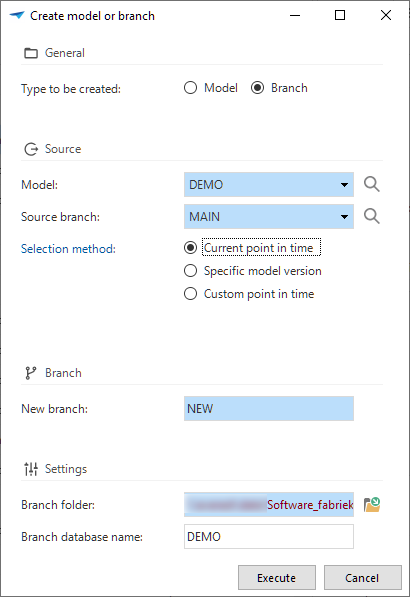 Create a future model or branch
Create a future model or branch
Function point analysis
The task that allows you to Calculate function points ![]() (menu Analysis > Function point analysis)
for a specific model or branch has changed due to the introduction of temporal tables.
(menu Analysis > Function point analysis)
for a specific model or branch has changed due to the introduction of temporal tables.
Previously, it was only possible to calculate the function points for a selected project and version based on the data in the project version at the time of the calculation.
Since we are using models and branches now, it is possible to calculate the function points based on one of the following situations:
- The current point in time
- A specific model version
- A specific point in time.
Historic information
Historical overviews are available on a large number of screens in the Software Factory, for example, menu Data > Data model > tab Tables Ctrl+H, or in the menu User interface > Messages Ctrl+H.
These overviews are no longer based on comparing two project versions but on temporal tables. They now include each point in time a record was created, updated, or deleted. This offers insight into a record's status in the various model versions. So, to consult a historical situation, you can refer to the historical overviews.
To improve readability, the query fields are now displayed in the Form instead of the list. An example is the Code field in the screenshot below. Also, changed columns will be shaded yellow, and records that have been added, changed, or deleted will be marked.
All changes are in the model's timeline, making it also visible if no changes have been made in a model version.
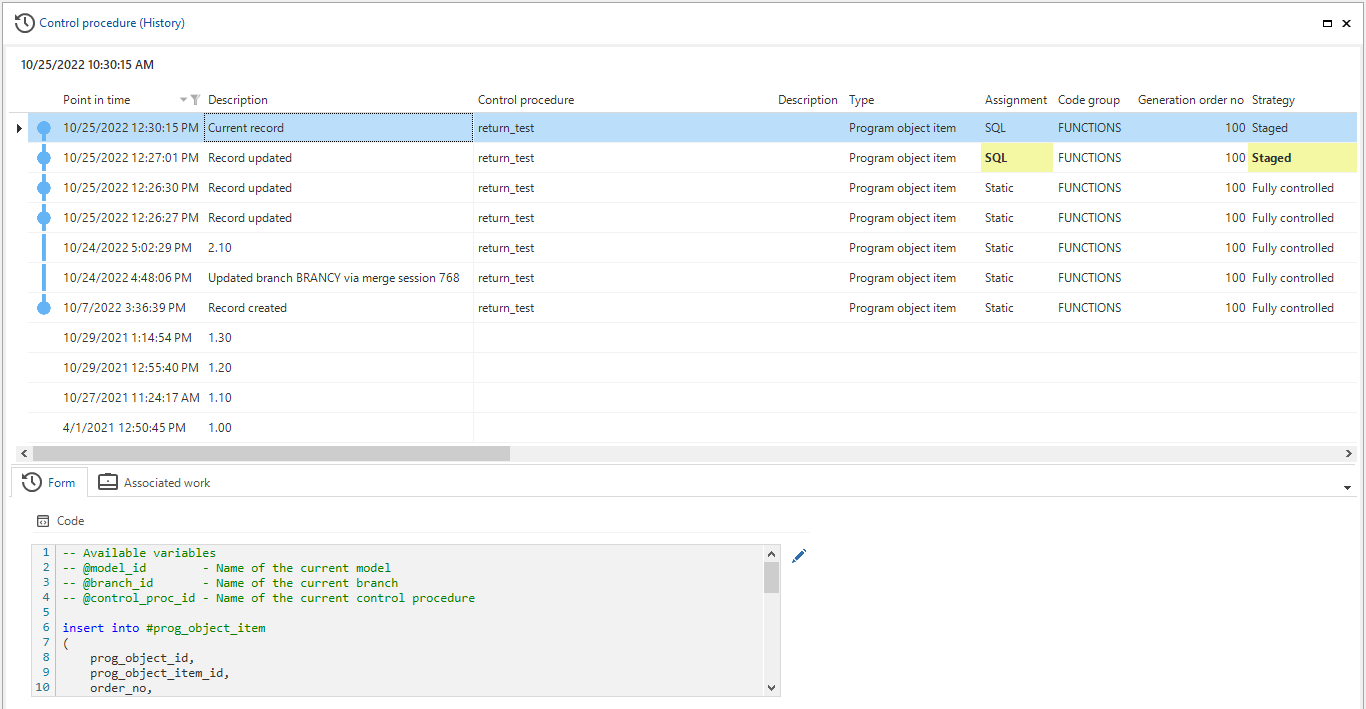 Improved model history insights
Improved model history insights
Software Factory - New and changed
Models - Export and import changed
changedPreviously, when exporting branches ![]() (menu Models > Model overview > tab Branches),
the file name was always
(menu Models > Model overview > tab Branches),
the file name was always model.dat.
So, when exporting multiple models, the file name could no longer accurately tell the model name and when the export had been created.
Therefore, the default name has been changed.
It now holds the date and time of the export, model and branch name, and the model.dat extension.
This name can be changed but note that .dat is the only allowed extension for importing a branch.
 New default name for exported model
New default name for exported model
In addition, The Export branch ![]() task now uses the Download file process action.
As a result, a user can now select a download folder and enter a name for the export file.
Previously a Write file action was used, so the file was always written to the project folder.
task now uses the Download file process action.
As a result, a user can now select a download folder and enter a name for the export file.
Previously a Write file action was used, so the file was always written to the project folder.
Models - Multiple live versions
changedIn menu Models > Model overview, the Multiple live versions setting has been moved from tab Models to tab Branches > tab Model settings due to the replacement of the status field. This setting allows multiple production versions.
 Multiple live versions as an option now available in tab Model settings
Multiple live versions as an option now available in tab Model settings
Data - Domain input constraints
Community idea Universal GUI Windows GUI with IndiciumWhen creating domains, it was already possible to add some static constraints (minimum and maximum values or lengths, and a pre-defined selection (Elements)). These constraints are applied to the database (stored data will be checked). Data is also checked by the UI and the API. However, if a domain is used in, for example, a view or a task, a static database constraint cannot be applied, (though the UI and API will still check the input).
Now, input constraints are available as a feature. This makes the Thinkwise Platform even more low code.
An Input constraint is a more dynamic extension of a domain constraint. It is a simple check on entered data at the domain level, similar to the minimum and maximum values or lengths. Data stored on the database will not be checked, but the UI and API will not accept unallowed input and not process it. Using these constraints, it is no longer necessary to create default or layout procedures to perform these checks.
The new tab Input constraints is available in the menu Data > Domains. You need to configure several settings to use input constraints.
- The Constraint type for evaluating the entered data can be an SQL expression or a Regular expression.
- The Timing can be Immediate (while entering the data), or On change (when the cursor leaves the field).
- You can add a Sequence no. when using multiple input constraints.
- The Expression needs to match the syntax of the chosen constraint type.
The following validations are available for input constraints:
- A domain input constraint uses an SQL expression in combination with Immediate timing.
- A domain input constraint with an SQL expression should generally refer to the input value.
- Domain input constraint is not used.
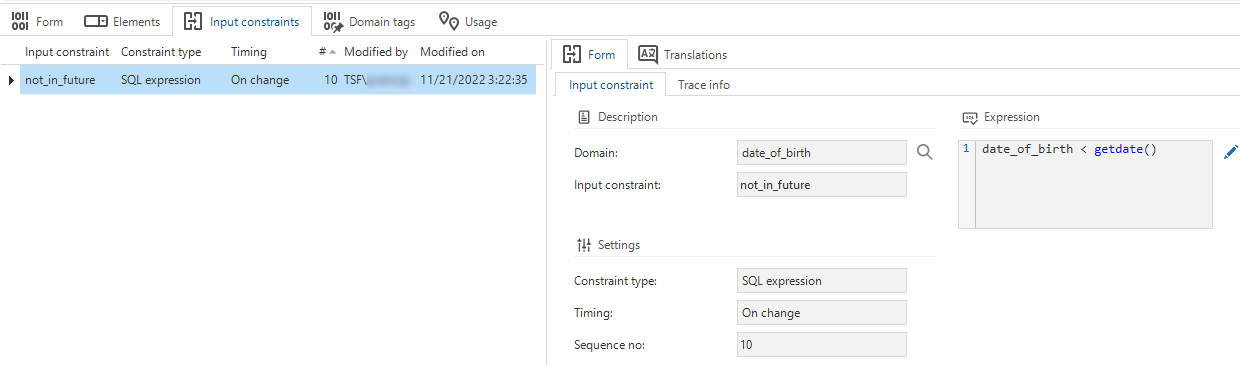 Domain input constraints
Domain input constraints
Process flows - Column 'API' renamed
changedIn process flows (menu Processes > Process flows > tab Process flows), the column and checkbox name API turned out to be confusing since every process flow is an API. Therefore, it has been renamed to Custom protocol. API alias has been renamed to Custom protocol alias.
 API renamed to 'Custom protocol'
API renamed to 'Custom protocol'
Process flows - Labels in the Output tab
new Community ideaWe have added explanatory labels to the Output tab of all process actions to indicate the difference between the available fields (menu Processes > Process flows > tab Process actions > tab Output).
 Explanatory labels in the Output tab
Explanatory labels in the Output tab
Process flows - Custom schedules disabled if no longer allowed
changedPreviously, if you disabled the Custom schedule allowed box in a system flow (menu Processes > Process flows), its custom schedules remained available after synchronizing to IAM. This has been changed. Now, if you disable this setting for a system flow and synchronize to IAM, all its custom schedules will be disabled.
Process flows - OAuth connectors
new changed Indicium Universal GUIWe have renamed the OAuth login connector to OAuth user login connector. This process action type always uses the authorization code grant type, which requires user interaction.
In addition, we have added a new process action type called OAuth server login connector. This connector uses the client credentials grant type that requires no user interaction or consent, though it may deviate regarding supported scopes or require some form of preemptive administrator consent. You can override the configured scope in this process action via the Scope input parameter. Output parameters include the Access token, the Token type, and the Expires in response values. This connector can be used in a system flow.
In the OAuth server settings (menu Models > Model overview > tab Branches > tab Oauth server), the options 'Request refresh token', 'Prompt', and 'Response type' now only relate to the OAuth user login connector. The screen has been updated to reflect this. The options are now grouped as User login.
The visualization in the process flow modeler clearly distinguishes between the two types of grant flows:
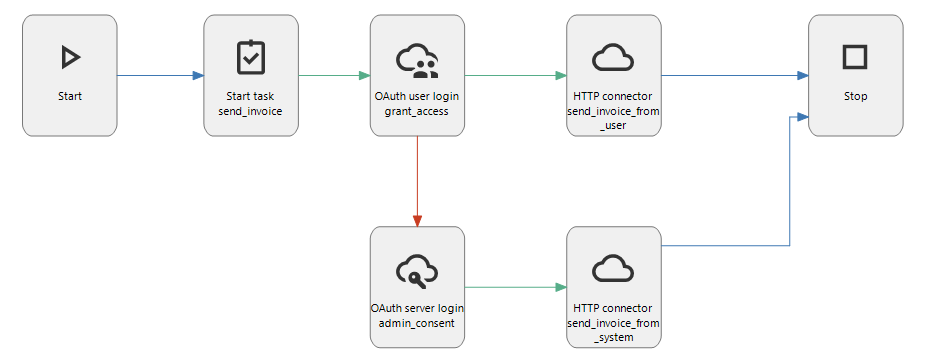 An Oauth User login and Server login connector in a process flow
An Oauth User login and Server login connector in a process flow
Process flows - New action 'Open link'
new Community ideaThe new process action Open link will open a URL. By default, the link opens in a new tab in the web browser, but you can change that with an input parameter.
In addition, this process action can either wait for the user to complete an action inside the opened link or to continue the process flow right after opening the link. You can use this, for example, to direct users to an external payment environment in a new tab. After a successful payment, the process flow will continue inside the application.
For the Universal GUI, this process action is available as of release 2023.1.10.
The URL should be preceded by https:// (e.g., https://www.thinkwisesoftware.com/).
The parameters Open in new tab and Process flow continue option are not yet supported.
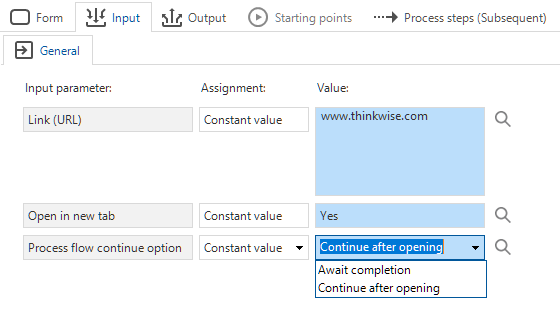 New process action: 'Open link'
New process action: 'Open link'
Process flows - New action 'Merge PDF'
new Community ideaWe have added a new process action to merge PDF files: Merge PDF. It requires an absolute path to a folder containing the PDF files that need to be merged. The files are merged in alphabetical order, as found in the source folder.
The output consists of the merged PDF file and a JSON array with the absolute path of all the merged files.
Process flows - New action 'Close all documents'
newWith the new process action Close all documents, all open documents can be closed in an instance. You can use this action, for example, when switching between different administrations inside your end application. This situation affects all documents, which therefore should be closed.
Process flows - New authentication type for HTTP connector
newWe have added a new Authentication type option to the HTTP connector process action. It is called Bearer. In the additional input parameter Bearer token, you have to provide the appropriate bearer access token for the HTTP connector.
Validations for this authentication type:
- Process action uses authentication type Bearer but also has a username/password combination specified.
- Process action uses authentication type Bearer but has no bearer access token assignment.
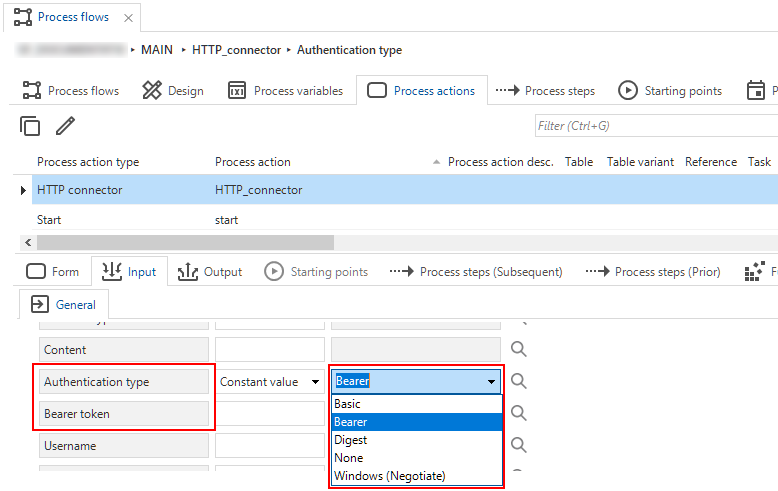 Bearer as a new authentication type
Bearer as a new authentication type
User interface - Separate tab for combined filters
changedIt used to be possible to include a column into a combined filter by selecting the In combined filter checkbox in menu User interface > Subjects > Data > tab Data > tab Filter.
However, this setting is independent of whether the filter is enabled or not (menu User interface > Subjects > tab Settings > tab Permissions > checkbox Filter). If the filter is disabled here, any column that is allowed in a combined filter will tell the GUI to show the combined filter component.
Since this situation has caused some confusion, we have decided to move the 'In combined filter' setting to its own tab.
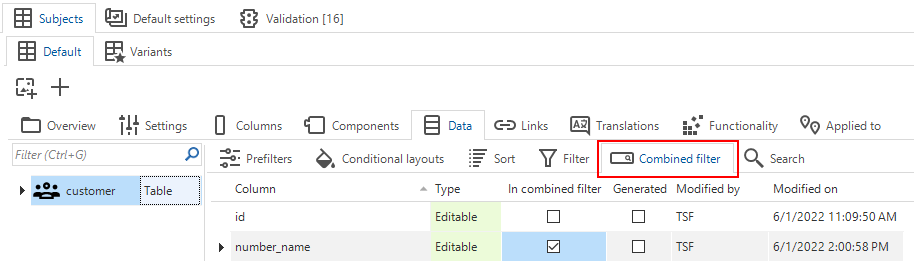 A new tab for the combined filter
A new tab for the combined filter
User interface - Set the component for a conditional layout
changed Windows GUI Web GUIIt is now possible to set the component where the conditional layout should be applied.
The setting Show conditional layout is available in the menu User interface > Subjects > tab Data. When selected, you can choose a Column and the component(s) the conditional layout should be applied to. The options are Grid, Form and Edit, Grid and Form, Grid only, and Form only.
These settings replace the existing ApplyConditionalLayout extended property.
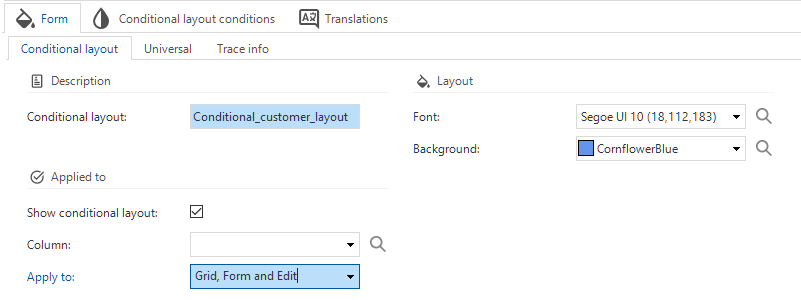 Conditional layout in the GUI instead of an extended property
Conditional layout in the GUI instead of an extended property
User interface - Icon repository
new changedWe improved the Icon repository by adding the possiblity to update an icon for all its related objects.
We have added a new task for this, Update icon usage for related objects ![]() .
You can use it to replace the selected icon with another one in all its assignments, for example, as a table icon, domain element icon, menu item icon, etc.
.
You can use it to replace the selected icon with another one in all its assignments, for example, as a table icon, domain element icon, menu item icon, etc.
This task can be applied to replace an icon with an existing or new one but is also helpful where duplicates of an icon exist.
 Update an icon for all assigned objects
Update an icon for all assigned objects
A change in the Icon repository is that we have limited the allowed extensions. First, every extension could be used for an icon. Now, it has been limited to .gif, .jpeg, .jpg, .png, .bmp, and .svg.
And finally, to improve finding an icon without knowing its name, we have added a visual overview to the Icon repository (menu User interface > Icons > tab Icon overview).
Once you have found the icon in the overview, you can select its row and obtain its name from the corresponding form field.
Or, you can select the icon and use task Go to icon ![]() .
Note that this task will bring you only approximately to the icon since the GUI cannot supply the row information.
.
Note that this task will bring you only approximately to the icon since the GUI cannot supply the row information.
![]() A visual overview in the Icon repository
A visual overview in the Icon repository
User interface - Exported theme file downloaded
changedThe Export theme ![]() task (menu User interface > Themes) now uses the Download file process action.
As a result, a user can now select a download folder and enter a name for the export file.
The default file name contains the model, branch, and date. This name can be changed.
The theme will be exported with a .json extension.
task (menu User interface > Themes) now uses the Download file process action.
As a result, a user can now select a download folder and enter a name for the export file.
The default file name contains the model, branch, and date. This name can be changed.
The theme will be exported with a .json extension.
Previously, a Write file task was used, so the file was always written to the project folder.
User interface - Custom look-up display column for Maps
Universal GUIBy default, a marker uses the tables' look-up display as a label in the Maps component. Now, it is also possible to use a custom label for markers. In menu User interface > Maps, you first need to select the Use custom label column checkbox. Then, you can select the Label column you wish to use as a label for the marker. If the custom label is empty, no label will be shown.
File storage - Azure Blob Storage support
new Universal GUI Community ideaAzure Blob Storage is now a supported file storage location. It is possible to authenticate with a managed identity, or by specifying the Tenant id, Client id and the Client secret.
- For each runtime configuration, you can set the file storage location in menu Maintenance > Runtime configurations > tab File storage locations or in menu Models > Model overview > tab Branches > tab Runtime configurations > tab File storage locations.
- For each branch, you can set the file storage location in menu Models > Model overview > tab Branches > tab File storage locations.
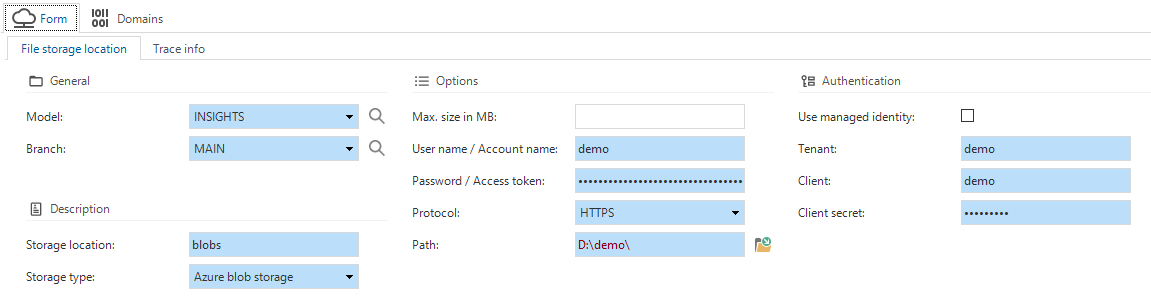 Azure Blob Storage as a file storage location
Azure Blob Storage as a file storage location
File storage - Azure files SAS token support
newAzure files as a storage type now requires a username/SAS (Shared Access Signature) token combination instead of a username/password combination.
The SAS token is required for all new Azure file storage configurations. Existing configurations have not been altered. However, if the username/password for an existing configuration is cleared, the password field will be hidden, and the SAS token will become mandatory.
- For each runtime configuration, you can set the file storage location in menu Maintenance > Runtime configurations > tab File storage locations or in menu Models > Model overview > tab Branches > tab Runtime configurations > tab File storage locations.
- For each branch, you can set the file storage location in menu Models > Model overview > tab Branches > tab File storage locations.
File storage - 'Storage' instead of 'disk'
changedIn the 2022.2 release, we have introduced new file storage system flow actions for writing code files, program objects, the manifest, and the IAM synchronization script. This means that files are no longer always written to disk. For this reason, we have replaced the occurrences of the term 'disk' with 'storage' where appropriate. Of course, write to disk remains available as a file storage type.
 An example of 'storage' instead of 'disk'
An example of 'storage' instead of 'disk'
Business logic/Processes/Data - Select objects to include in copy tasks
Community ideaFor a number of copy ![]() tasks (for a table, task, report, and subroutine), we have added checkboxes that allow you
to select or deselect the objects that need to be copied.
tasks (for a table, task, report, and subroutine), we have added checkboxes that allow you
to select or deselect the objects that need to be copied.
- Copying a task or report now contains the options to include the functionality assignments, or the respective table tasks or reports.
- Copying a subroutine now contains the option to include the functionality assignments.
If you deselect the functionality assignments option, the object will not be assigned to any control procedure. You can use this to create a bare object, create a new control procedure, and then assign the object to it.
Copying a table has the most options as it is used frequently to copy an existing table.
By default, it will copy the table, the columns, and all settings, such as grid and form order, sorting, conditional layout, and prefilters. Additionally, you can include component data (cube, maps, scheduler), table reports and table tasks, and functionality assignments.
New is the option to copy detail and look-up references. To mimic the behavior in previous platform versions, references are not included automatically.
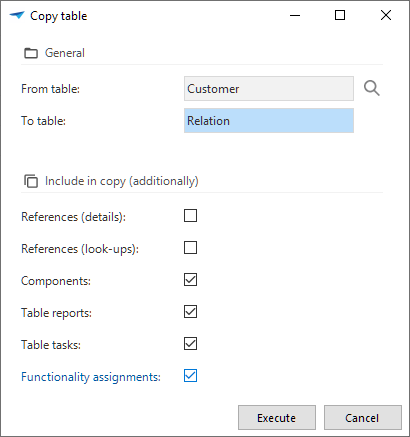 Select objects to include in copying a table
Select objects to include in copying a table
Business logic - Abandon control procedure
newSometimes, changes to a control procedure need to be rolled back. This used to be quite complicated, especially if templates had been deleted.
With the new task Abandon control procedure changes ![]() (menu Business logic > Functionality > tab Control procedure),
it is now possible to revert all changes made to a control procedure.
As a result, it will be exactly like the last time it was approved and completed.
For a control procedure with the Assignment setting 'Static', it is also possible to revert the assignments and parameters.
(menu Business logic > Functionality > tab Control procedure),
it is now possible to revert all changes made to a control procedure.
As a result, it will be exactly like the last time it was approved and completed.
For a control procedure with the Assignment setting 'Static', it is also possible to revert the assignments and parameters.
This new task is only available for control procedures that have not been completed yet, so in development, review, etc.
 Abandon changes in a control procedure
Abandon changes in a control procedure
Business logic - Code search for inactive control procedures
new Community ideaThe Code search functionality (menu Business logic > Code search) now has a new option for extending your search to inactive control procedures. Results for inactive control procedures will be displayed in grey.
By default, inactive control procedures will no longer be included in the search result.
Because of this addition, we also rearranged the options in this screen to make it more intuitive.
 Extend your code search to inactive code
Extend your code search to inactive code
Business logic - Obtain the original login user
Universal GUI Windows GUI new Community ideaIt was already possible to obtain the current user by calling the tsf_user() function.
However, this function cannot recognize whether the user is simulated or not.
Simulating a user means that someone is using the application with someone else's account.
This can be useful but may also pose a security risk by being able to change information under someone else's name.
To resolve this risk, we have introduced a new function that returns the original login user, called tsf_original_login().
Regardless if the user simulates another user, this function will return the original user's name.
We recommend reviewing your use of the tsf_user() function and consider changing it to tsf_original_login().
The latter is great for tracking changes made by the original user.
The tsf_user() function is used best for data selection filters that must return the same data during simulation.
For instance, when a prefilter limits data to the current user, using tsf_user() will return the same data when the current user is simulated.
Quality - Smoke tests
Smoke tests are now available in the Software Factory.
Smoke tests are preliminary tests to reveal simple failures severe enough to, for example, reject an upcoming software release. In the Software Factory, you can use smoke tests to ensure a basic quality level of SQL queries in your application. SQL queries that are not placed on the database as application logic may be malformed. Running smoke tests will discover these malformed queries in advance instead of at runtime.
The smoke tests also detect editable views without RDBMS editing support, instead-of triggers, or handlers. They will also detect outdated parameterization of logic. Furthermore, smoke tests can detect some forms of outdated dependencies for views, triggers, and stored procedure logic on the database.
Note that due to the introduction of smoke tests, the base model DEFAULT_TEST_CASES has become obsolete and will no longer be supplied.
The following items are tested:
- Via a select query
- SQL prefilters
- Views
- Calculated columns
- Calculated columns (function)
- Expression columns
- Column default expressions
- Task parameter default expressions
- Report parameter default expressions
- Process variable default expressions
- Scalar functions
- Table-valued functions.
- Within a transaction that is rolled back, using null values as input:
- Default logic
- Layout logic
- Context logic
- Badge logic
- Change detection logic
- Within a transaction that is rolled back, firing with 0 affected rows:
- Insert triggers
- Instead-of insert triggers
- Update triggers
- Instead-of update triggers
- Delete triggers
- Instead-of delete triggers.
Procedure subroutines, handlers, and tasks are not included, since knowledge of the parameterization is required to execute these without causing errors. You can use unit tests to achieve the desired coverage.
The smoke tests are available in the menu Quality > Smoke tests. They only support SQL Server as a database platform.
The smoke tests can only run ![]() as a single unit. Running a test for an individual item (like a prefilter) is currently not possible.
as a single unit. Running a test for an individual item (like a prefilter) is currently not possible.
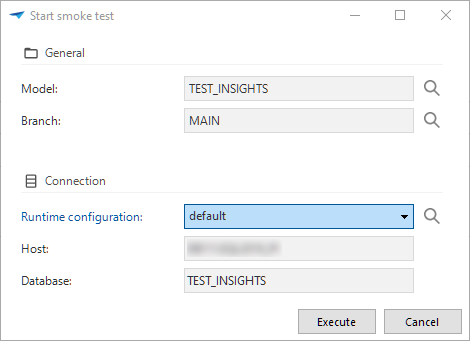 Smoke tests ensure a basic quality level of SQL queries in your application
Smoke tests ensure a basic quality level of SQL queries in your application
Quality - Delete a test run
newYou can now use the delete ![]() button to delete a manual test run (menu Quality > Test runs).
Any findings attached to the deleted test run will be set to 'inactive' but remain available in the work overview (menu Specification > Work overview).
button to delete a manual test run (menu Quality > Test runs).
Any findings attached to the deleted test run will be set to 'inactive' but remain available in the work overview (menu Specification > Work overview).
Quality - Usability unit tests improved
changed fixedWe have improved the usability of the unit tests in several ways:
- The Maintenance tab is no longer available. Instead, you can now navigate directly to a unit test's Form tab.
- Tabs Object overview and Mock data have been moved to a higher level, so it is no longer necessary to enter the details of a unit test to navigate to these tabs.
- We expanded the conditions for setting up a row filter in a unit test for an update or delete trigger. Now, the same filter conditions are available as in the standard GUI filter (CTRL+R) and for the prefilter conditions. Previously, the only filter conditions were 'empty', 'is not empty', and 'equal to'.
- It is possible again to remove a unit test.
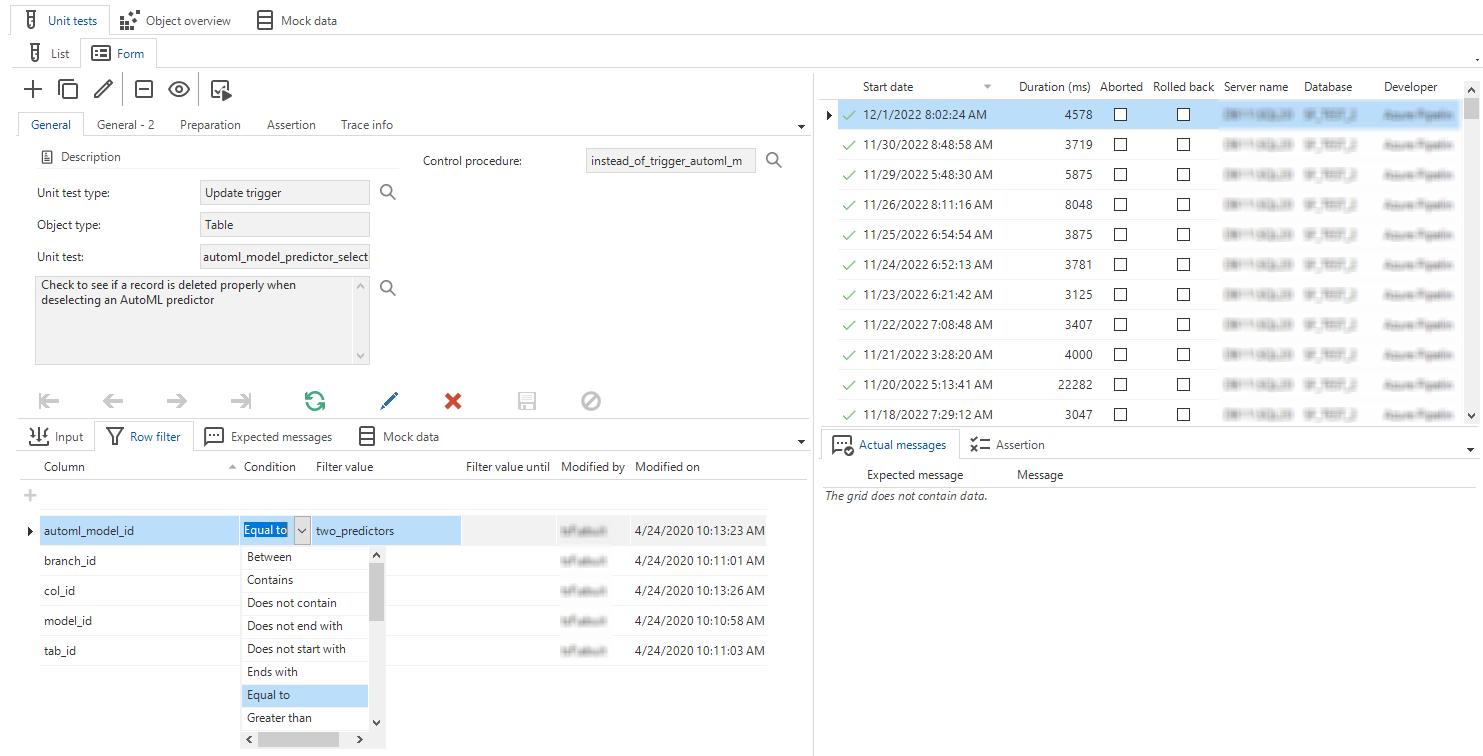 Create a unit test in the Form
Create a unit test in the Form
Quality - Undo the (dis)approval of a control procedure
new Community ideaIt is now possible to undo the approval or disapproval of a control procedure.
After approving ![]() or disapproving
or disapproving ![]() a control procedure,
the Undo
a control procedure,
the Undo ![]() task becomes available (menu Quality > Code review > tab Code review).
task becomes available (menu Quality > Code review > tab Code review).
When an approval or disapproval is undone, snapshots of code that were present for the selected change log record will be erased, and the control procedure status reset to Review. This way, the live code will be visible for review again.
This functionality is intended to quickly undo a wrong choice when reviewing a control procedure, not to make historical corrections. For this reason, it is allowed only to undo the most recent review for a control procedure.
Quality - Validations
changed newWhen creating your own validations (menu Quality > Validations > Maintenance), the field Severity is now mandatory. The reason is that a validation without a severity will not show in the validation tree.
During the upgrade to version 2023.1, all validations without a severity level will be set to 'Warning'. You can change this after the upgrade.
We have also added several new validations:
- View with an enabled prefilter that is locked or hidden - Checks if a view contains an enabled prefilter that is locked or hidden. Depending on the situation, this could lead to a loss of performance. This validation reminds you to consider including the prefilter conditions in the view code.
- Test case without object - Checks if a test case (process test) is provided with an object, such as a table, report, or task (variant). This prevents the test case from failing with the message: "Cannot perform action 'Open undefined".
- Process action starts multiple process flows - Checks for start actions used in multiple process flows. This can lead to a situation where only the first process flow in alphabetical order is executed when the start action is triggered through an API call.
- Multiple detail tabs with the same detail group - Identifies situations where the same detail group is assigned to multiple detail tabs within the same screen type. This is not supported by the GUI.
- Column/task parameter/report parameter uses a reserved name - Identifies whether a column, task parameter, or report parameter uses a reserved name. This prevents problems due to naming conflicts in Indicium and GUIs using Indicium.
- Index contains no index columns - This identifies basically the same situation as when a table contains no columns.
Access control - Tags for roles screen
newAs part of our tagging concept, we have added Role tag as a detail tab to the Roles screen (menu Access control > Roles).
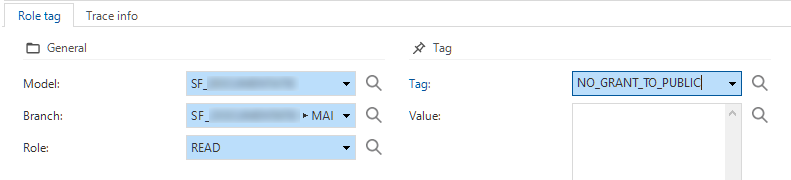 Role tags for roles
Role tags for roles
Deployment - Source code generation
new changed Community ideaIn the Creation process, the Generate source code tab now shows the code groups that are generated. We have added numbers to indicate the number of program objects that need to be generated per code group. This provides more insight into the progress of the process.
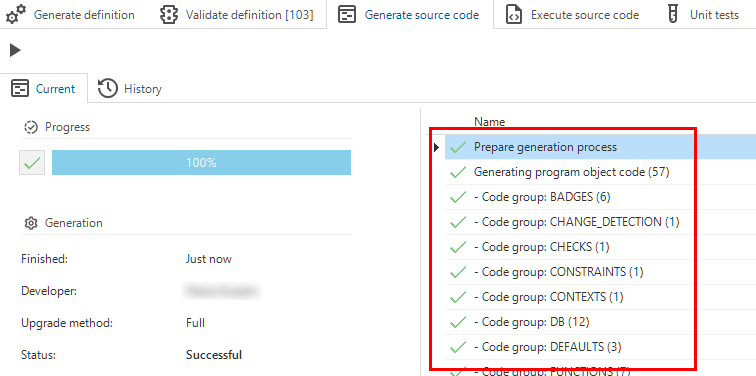 The number of program objects per code group
The number of program objects per code group
Another new feature is, that the Generate source code process will now log errors when they are encountered. You can find the error log in the menu Maintenance > Jobs > Generate source code.
We have also added an improvement to the source code generation.
From now on, wherever possible for the supported programming languages,
the Software Factory will use the CREATE OR ALTER statement for SQL Server and CREATE OR REPLACE for DB2 and Oracle.
This change ensures that when objects are altered or replaced, any rights present on them remain intact and do not need to be reapplied.
Due to this change, the next (smart) branch upgrade will take longer as most source code is affected and needs to be regenerated.
Deployment - Pool user credentials
Universal GUI newWhen using the Software Factory in Universal GUI, it is now possible to store the pool user credentials in IAM or the Software Factory. If added, these credentials are safely encrypted and will be used instead of the credentials stored in Indicium's appsettings.json file.
In IAM, in the menu Authorization > Applications, you can set the pool user credentials with the task: Set pool user credentials. After entering the username and password, they are stored encrypted in the database. In tab Form, the checkbox Custom pool user set will be selected automatically. To reset the credentials and use them as stored in the appsettings.json file instead, you can use the Reset pool user credentials task.
Since the Software Factory is only partially available for the Universal GUI, we have added the menu items for adding the user credentials to the runtime and IAM configurations (menu Maintenance > Runtime configurations and menu Maintenance > IAM configurations).
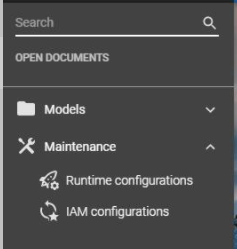 Menu items for user credentials in the Software Factory for the Universal GUI
Menu items for user credentials in the Software Factory for the Universal GUI
Deployment - New procedure for automation
If you are using deployment automation, a new procedure is available. It is called cancel_all_jobs. You can use it to ensure that no other jobs are running.
This can be a further improvement in your CI/CD processes.
Maintenance - Automatic removal of job information
newThe Software Factory uses Jobs to ensure that processes like Generate definition and Validate definition are run by Indicium.
However, the job information is usually not important enough to store for a longer period of time. To clean up this data, a new setting named Job retention (in days) has become available in menu Maintenance > Configuration > group Environment settings > field Job retention (in days). The default value is 14 (days).
Every day at 8:00 PM UTC, the Software Factory will remove the job information based on the value for the setting. The clean-up process will remove all related data for jobs that have finished and exceeded the job retention period.
Software Factory - Fixed
Creation - Job successful after creating a database
In the Creation process, when the database is not found but the db/create scripts are present, the database will be created anyway.
However, in that case the connect job would be marked as 'failed'.
As a result, the source code would not be executed, either.
From now on, the connect job will be marked as 'completed' in this situation.
Creation - Database creation for non-default runtime configurations
In the Creation process, if you select a runtime configuration with a database that does not yet exist,
the db code file will now be adjusted to create the right database.
Previously, the database that belonged to the default runtime configuration would be created.
Creation - Merging base models into work model
In the Creation process, we have changed the procedure Merging base models into work models in the Generate definition process.
This procedure included data columns only in the insert part of the merge.
This has been resolved. Now data columns are also updated from the base model when modified.
Creation - System flow for notification e-mail
When the Generate definition process is started, a system flow (if configured) should automatically send an e-mail as a notification. Unfortunately, this system flow resulted in an error. This has been resolved.
Deployment - Write deployment manifest follow up
When creating a deployment package (menu Deployment > Deployment package), the manifest would always be written to disk, even when its previous jobs had failed. Now, this job will be canceled if the previous jobs have failed.
Inconsistent line endings in code
When opening program objects or code files in external editors, like SQL Server Management Studio, sometimes a warning would show about line endings. This has been fixed for badges, change detection, contexts, defaults, handlers, layouts, and processes with multiple groups of parameters.
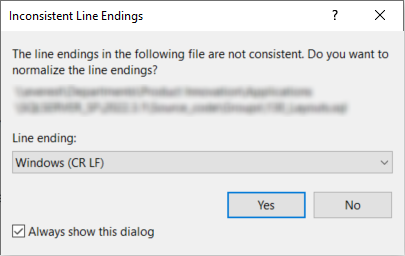 Example: inconsistent line endings
Example: inconsistent line endings
Process flows - Hidden columns in process actions
Universal GUIDue to how the process actions Change filters and Change sort order are handled by the Universal GUI, they need hidden columns to be considered 'Hidden' instead of 'Unauthorized'. When the column is considered 'Hidden', the GUI can use it to change the filter or sort order for the user. A fix has been made to ensure that any hidden columns assigned to an input value inside the process actions Change filters and Change sort order are effectively hidden.
Process flows - Program object for process action without a next step
Now, a program object (and thus a process procedure) will be available for every process action when Use process procedure is selected (menu Processes > Process flows > tab Process actions > tab Form > tab Performance).
Previously, no program object would be created for process actions without a successor. This led to missing program objects if the successor was added later. An extra (code group) generation was necessary to make the program objects available for static assignments.
The situation where a process action does not have a successor but Use process procedure has been selected is still incorrect, but will now be signaled with a validation.
During the upgrade to release 2023.1, the current incorrect situations will be corrected by deselecting the checkbox Use process procedure. Since this checkbox ensures the GUI executes the process procedure, it would cause a problem if no process procedure is available.
Foreign key index creation on composite primary keys
Indexes for foreign keys were not created correctly if the foreign key column was part of a composite primary key. This has been fixed.
Data - Delete undesired objects in data migration
When a table is changed to a view, or a regular column to an expression column, the data migration would keep these objects. This led to errors during code execution. This has been solved. The undesired objects will be deleted now.
Quality - Unit testing objects with @error_msg parameter
Community ideaUnit tests executed on defaults, layouts, procedures, etc. that use a parameter named '@error_msg' will no longer cause the unit test to fail.
Intelligent Application Manager - New and changed
Authorization - Translation management role
Community idea newIn a time where more and more applications are multilingual, the need for a dedicated translator grows. To allow a translator access to the model translations, we have created a new role to grant access to the Translation section of the Software Factory (menu User interface > Translation). In IAM, you can grant translators access by assigning the Translation management role to the correct user group (menu Authorization > User groups > tab Authorization).
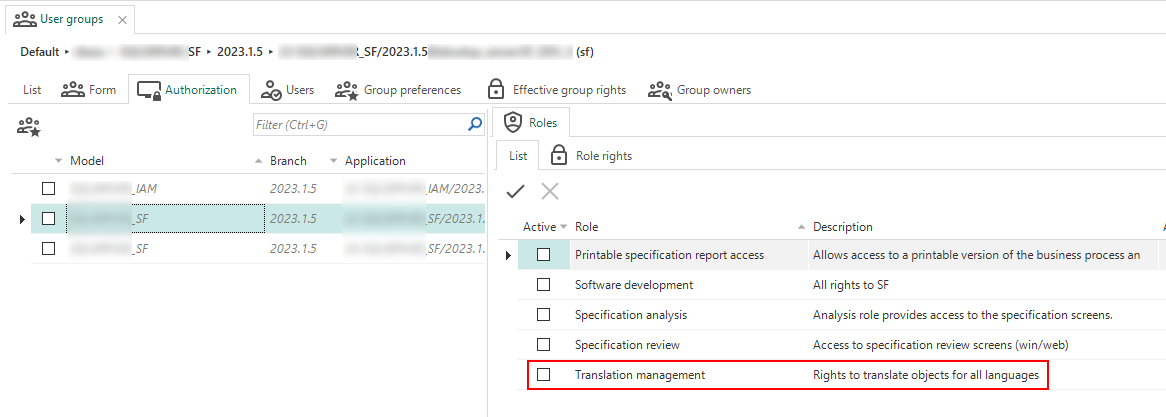 Translation management role to grant access to the Software Factory's translations
Translation management role to grant access to the Software Factory's translations
Performance - get_gui views performance optimizations
changed Windows GUI Web GUIWhen starting an end product created with the Thinkwise Platform, the model must be loaded. For the Windows and Web GUIs, this is done by using get_gui views. These views load the data in the most efficient way, which is a challenge because the model and amount of data can differ enormously per customer. We always strive to offer a solution that works as well as possible for everyone.
In this release, we provided optimizations that improve the performance for four procedures used in the IAM get_gui views:
- proc_get_gui_col
- proc_get_gui_ref
- proc_get_gui_ref_col
- proc_get_gui_tab_variant_col.
Intelligent Application Manager - Fixed
Users - Start objects in Universal GUI
Universal GUIA user can be linked to multiple user groups using the same start object. This previously led to starting the start object several times. This no longer happens, it will now start only once.
Process flows - Schedules with frequency type 'once'
A problem occurred with custom process flow schedules using the frequency type 'once' that were copied from an existing schedule. Some fields would be mandatory and hidden, so the frequency type 'once' could not be used correctly. This has been fixed, schedules can be used properly now.
Data model changes
Data model changes for the Software Factory and IAM meta-models are listed here. This overview can be used as a reference to fix dynamic control procedures, dynamic model code or custom validations after an upgrade.
Changes Software Factory
Table changes
Changes
| SF - From table | SF - To table |
|---|---|
| - | code_file_code |
| - | code_generation_log |
| - | dom_input_constraint |
| - | model_settings |
| - | model_vrs |
| - | model_vrs_data_migration_col |
| - | model_vrs_data_migration_tab |
| - | pending_change_log |
| - | pending_change_log_comment |
| - | role_tag |
| - | scheduler |
| - | scheduler_view |
| - | smoke_test |
| - | smoke_test_step |
| - | tab_variant_combined_filter |
| - | tab_variant_scheduler |
| - | tab_variant_scheduler_view |
| - | usr_session |
| - | validation_msg_approved_temp |
| control_proc_history | - |
| control_proc_template_history | - |
| future_project | future_model |
| future_project_vrs | future_branch |
| linked_project | linked_model |
| project | model |
| project_tag | model_tag |
| project_vrs | branch |
| project_vrs_appl_lang | branch_appl_lang |
| project_vrs_tag | branch_tag |
| sf_info | - |
| validation_msg_approved_branch | - |
| validation_msg_approved_project_vrs | - |
| validation_status | - |
| vrs_control_col | data_migration_col |
| vrs_control_tab | data_migration_tab |
Column changes
project_id and project_vrs_id are renamed to model_id and branch_id.
This is also automatically done in all scripts during the upgrade.
All affected tables are listed below, but kept out of the changes overview.
Affected tables
- ambiguous_expression
- audio_file
- automl_model
- automl_model_fitted
- automl_model_predictor
- automl_model_target
- automl_model_training_data
- change_log
- change_log_comment
- change_log_template
- code_file
- code_generation
- code_generation_step
- code_grp
- code_grp_tag
- code_search
- code_search_result
- col
- col_data_sensitivity
- col_tag
- concept_abbr
- conditional_layout
- conditional_layout_condition
- conditional_layout_tag
- control_proc
- control_proc_log
- control_proc_tag
- control_proc_template
- control_proc_template_statistics_dirty
- cube
- cube_field
- cube_tag
- cube_view
- cube_view_constant_line
- cube_view_field
- cube_view_field_conditional_layout
- cube_view_field_filter
- cube_view_field_total
- cube_view_grp
- cube_view_tag
- data_set
- data_set_tab
- database_file
- default_usr_grp
- default_usr_grp_role
- definition_generation
- definition_generation_step
- definition_validation
- deployment_module
- deployment_module_role
- deployment_run
- deployment_run_step
- design_module
- design_spec
- design_spec_appendix
- design_spec_line
- design_spec_line_comment
- design_spec_line_req
- design_spec_line_target
- design_spec_model_link
- design_spec_req
- diagram
- diagram_ref
- diagram_ref_control_point
- diagram_tab
- document
- dom
- dom_tag
- drag_drop
- drag_drop_parmtr
- elemnt
- elemnt_tag
- execute_object_code
- execute_source_code
- execute_source_code_step
- extender
- external_object
- external_object_tag
- file_storage
- file_storage_configuration
- file_storage_extension_whitelist
- font
- function_point_analysis
- function_point_analysis_function
- generate_object_code
- generate_sync_scripts
- generation_email
- help_index
- icon
- icon_tag
- indx
- indx_col
- indx_tag
- job
- list_bar_grp
- list_bar_grp_tag
- list_bar_item
- list_bar_item_tag
- map
- map_base_layer
- map_data_mapping
- map_overlay
- menu
- module_grp
- module_grp_tag
- module_item
- module_item_tag
- msg
- msg_option
- new_object_verified
- oauth_server
- oauth_server_configuration
- object_name
- offline_code_file
- partition_boundary
- partition_scheme
- platform
- platform_excluded_menu
- platform_excluded_process_flow
- post_sync_code
- printer
- process
- process_action
- process_action_automl_model_predictor_input_parmtr
- process_action_col_input_parmtr
- process_action_fixed_input_parmtr
- process_action_output_parmtr
- process_action_report_parmtr_input_parmtr
- process_action_start_report
- process_action_start_report_variant
- process_action_start_tab
- process_action_start_tab_variant
- process_action_start_task
- process_action_start_task_variant
- process_action_sub_flow_input_parmtr
- process_action_tab_prefilter_input_parmtr
- process_action_tag
- process_action_task_parmtr_input_parmtr
- process_flow
- process_flow_schedule
- process_flow_tag
- process_step
- process_step_control_point
- process_step_tag
- process_tag
- process_variable
- prog_object
- prog_object_archive
- prog_object_item
- prog_object_item_parmtr
- prog_object_parmtr
- reachable_object
- reachable_report
- reachable_tab
- reachable_task
- ref
- ref_col
- ref_col_tag
- ref_tag
- refresh_grp
- report
- report_conditional_layout
- report_conditional_layout_condition
- report_conditional_layout_tag
- report_parmtr
- report_parmtr_tag
- report_ref
- report_ref_col
- report_ref_col_tag
- report_ref_tag
- report_tag
- report_variant
- report_variant_form
- report_variant_look_up
- report_variant_parmtr
- report_variant_report_conditional_layout
- report_variant_tag
- req
- req_appendix
- req_baseline
- req_baseline_req
- req_baseline_req_diagram_html
- req_baseline_req_platform
- req_baseline_req_review
- req_comment
- req_diagram_html
- req_diagram_link
- req_diagram_link_control_point
- req_diagram_node
- req_platform
- req_tag
- role
- role_col
- role_cube_field
- role_cube_view
- role_list_bar_grp
- role_list_bar_item
- role_menu
- role_module_grp
- role_module_item
- role_process
- role_process_flow
- role_ref
- role_report
- role_report_parmtr
- role_subroutine
- role_tab
- role_tab_prefilter
- role_tab_report
- role_tab_task
- role_task
- role_task_parmtr
- role_tile
- role_tile_grp
- runtime_configuration
- runtime_extended_property
- screen_component
- screen_component_property
- screen_component_tag
- screen_type
- screen_type_breakpoint
- sequence
- sf_upgrade_validation_msg
- sql_analysis_issue
- storage
- sub_name_excluded_object
- subroutine
- subroutine_option
- subroutine_parmtr
- subroutine_parmtr_tag
- subroutine_return_col
- subroutine_tag
- subroutine_type
- subroutine_type_option
- subroutine_type_option_value
- sync_run
- sync_script
- tab
- tab_check_constraint
- tab_data
- tab_data_col
- tab_page_control
- tab_prefilter
- tab_prefilter_col
- tab_prefilter_grp
- tab_prefilter_tag
- tab_report
- tab_report_grp
- tab_report_parmtr
- tab_tab_drag_drop
- tab_tab_variant_drag_drop
- tab_tag
- tab_task
- tab_task_grp
- tab_task_parmtr
- tab_variant
- tab_variant_card_list
- tab_variant_col
- tab_variant_conditional_layout
- tab_variant_cube
- tab_variant_cube_view
- tab_variant_detail
- tab_variant_filter
- tab_variant_form
- tab_variant_grid
- tab_variant_look_up
- tab_variant_map
- tab_variant_map_base_layer
- tab_variant_map_data_mapping
- tab_variant_map_overlay
- tab_variant_prefilter
- tab_variant_report
- tab_variant_search
- tab_variant_sort
- tab_variant_tab_drag_drop
- tab_variant_tab_variant_drag_drop
- tab_variant_tag
- tab_variant_task
- tab_variant_tree
- tag
- task
- task_conditional_layout
- task_conditional_layout_condition
- task_conditional_layout_tag
- task_parmtr
- task_parmtr_tag
- task_ref
- task_ref_col
- task_ref_col_tag
- task_ref_tag
- task_tag
- task_variant
- task_variant_form
- task_variant_look_up
- task_variant_parmtr
- task_variant_tag
- task_variant_task_conditional_layout
- template_prog_object_item
- template_prog_object_item_parmtr
- test_case
- test_case_control_proc
- test_case_run
- test_msg
- test_run
- test_scenario_run
- test_step
- test_step_check
- test_step_result
- test_step_run
- test_suite
- test_unit_test
- theme
- theme_tag
- tile
- tile_grp
- tile_grp_tag
- tile_tag
- transl_object
- transl_object_transl
- unit_test
- unit_test_col_filter
- unit_test_col_handler
- unit_test_col_input
- unit_test_col_output
- unit_test_col_type
- unit_test_data_set
- unit_test_fixed_parmtr_input
- unit_test_fixed_parmtr_output
- unit_test_msg
- unit_test_process_step_input
- unit_test_process_step_output
- unit_test_process_variable_input
- unit_test_process_variable_output
- unit_test_ref_output
- unit_test_report_parmtr_input
- unit_test_report_parmtr_output
- unit_test_report_parmtr_type
- unit_test_result
- unit_test_result_assertion
- unit_test_result_mismatch
- unit_test_result_msg
- unit_test_result_parmtr
- unit_test_result_parmtr_type
- unit_test_subroutine_parmtr_input
- unit_test_subroutine_parmtr_output
- unit_test_tab_report_output
- unit_test_tab_task_output
- unit_test_task_parmtr_input
- unit_test_task_parmtr_output
- unit_test_task_parmtr_type
- usr_role_simulation
- usr_runtime_configuration
- validation
- validation_grp
- validation_log
- validation_modeler
- validation_msg
- validation_msg_approved
- validation_msg_assigned
Changes
| SF - From table | SF - From column | SF - To column | New column - Mandatory | New column - Default value |
|---|---|---|---|---|
| change_log | originated_in_project_id | originated_in_model_id | - | - |
| change_log | originated_in_project_vrs_id | originated_in_branch_id | - | - |
| change_log_comment | - | history_type | 0 | NULL |
| change_log_comment | - | template_id | 0 | NULL |
| code_search | - | include_inactive_control_proc | 1 | 0 |
| conditional_layout | - | apply_conditional_layout | 1 | 0 |
| conflict_resolvement_type | - | origin_apply | 0 | NULL |
| control_proc | - | active | 1 | 1 |
| definition_generation | - | model_vrs_name | 0 | NULL |
| definition_generation | - | vrs_control_branch_id | 0 | NULL |
| definition_generation | - | vrs_control_model_vrs_id | 0 | NULL |
| deployment_run | - | sync_as_model_id | 0 | NULL |
| deployment_run | - | sync_as_branch_id | 0 | NULL |
| deployment_run | project_vrs_id | model_vrs_name | - | - |
| file_storage | - | sas_token | 0 | NULL |
| file_storage | - | use_managed_identity | 1 | 0 |
| file_storage | - | azure_tenant_id | 0 | NULL |
| file_storage | - | azure_client_id | 0 | NULL |
| file_storage | - | azure_client_secret | 0 | NULL |
| file_storage_configuration | - | sas_token | 0 | NULL |
| file_storage_configuration | - | use_managed_identity | 0 | NULL |
| file_storage_configuration | - | azure_tenant_id | 0 | NULL |
| file_storage_configuration | - | azure_client_id | 0 | NULL |
| file_storage_configuration | - | azure_client_secret | 0 | NULL |
| map | - | use_custom_label_col_id | 1 | 0 |
| map | - | label_col_id | 0 | NULL |
| map_data_mapping | - | dom_id | 1 | NULL |
| merge_conflict | trunk_delta_type | origin_delta_type | - | - |
| merge_conflict | trunk_delta_action_id | origin_delta_action_id | - | - |
| merge_conflict_type | trunk_action_type | origin_action_type | - | - |
| merge_session | - | origin_branch_id | 0 | NULL |
| merge_session | - | origin_model_vrs_id | 0 | NULL |
| merge_session | - | merge_from_branch_id | 1 | NULL |
| merge_session | - | merge_into_branch_id | 1 | NULL |
| process_flow | api | custom_protocol | - | - |
| process_flow | api_alias | custom_protocol_alias | - | - |
| runtime_configuration | - | encrypted_user_name | 0 | NULL |
| runtime_configuration | - | encrypted_password | 0 | NULL |
| sf_configuration | - | job_retention | 0 | 14 |
| sf_configuration | - | show_quality_dashboard | 1 | 1 |
| sf_configuration | default_project_folder_spec | default_model_folder_spec | - | - |
| sf_configuration | default_project_vrs_increment | default_model_vrs_increment | - | - |
| sf_upgrade_validation_msg | - | from_sf_model_vrs | 0 | NULL |
| sf_upgrade_validation_msg | - | to_sf_model_vrs | 0 | NULL |
| subroutine | legacy_api | basic_api | - | - |
| sync_run | - | sync_as_model_id | 0 | NULL |
| sync_run | - | sync_as_branch_id | 0 | NULL |
| sync_target_iam | - | encrypted_user_name | 0 | NULL |
| sync_target_iam | - | encrypted_password | 0 | NULL |
| tab_variant_conditional_layout | - | apply_conditional_layout | 0 | NULL |
| tab_variant_map_data_mapping | - | dom_id | 1 | NULL |
| test_scenario | last_run_project_id | last_run_model_id | - | - |
| test_scenario | last_run_project_vrs_id | last_run_branch_id | - | - |
| thinkstore | type_of_project | type_of_model | - | - |
| unit_test_col_filter | - | filter_value_until | 0 | NULL |
| work | planned_project_id | planned_model_id | - | - |
| work | planned_project_vrs_id | planned_branch_id | - | - |
| work_log | planned_project_id | planned_model_id | - | - |
| work_log | planned_project_vrs_id | planned_branch_id | - | - |
Changes Intelligent Application Manager
Table changes
Changes
| IAM - From table | IAM - To table |
|---|---|
| - | dom_input_constraint |
| - | scheduler |
| - | scheduler_view |
| - | tab_variant_scheduler |
| - | tab_variant_scheduler_view |
| project | model |
| project_vrs | branch |
| sf_info | - |
Column changes
project_id and project_vrs_id are renamed to model_id and branch_id.
This is also automatically done in all scripts during the upgrade.
All affected tables are listed below, but kept out of the changes overview.
Affected tables
- advice
- appl_lang
- automl_model
- automl_model_predictor
- automl_model_target
- col
- conditional_layout
- conditional_layout_condition
- cube
- cube_field
- cube_view
- cube_view_constant_line
- cube_view_field
- cube_view_field_conditional_layout
- cube_view_field_filter
- cube_view_field_total
- default_usr_grp
- default_usr_grp_role
- deployment_module
- deployment_module_role
- drag_drop
- drag_drop_link
- drag_drop_parmtr
- elemnt
- expression_dependency
- extender_property
- font
- get_gui_cache
- gui_appl
- gui_appl_admin
- gui_appl_authorization
- gui_appl_deployment_module
- gui_appl_pref_col
- gui_appl_pref_report_parmtr
- gui_appl_pref_task_parmtr
- gui_appl_transl
- help_index
- iam_extended_property
- iam_file_storage
- iam_oauth_server
- iam_printer
- iam_process_flow
- iam_process_flow_schedule
- list_bar_item
- log_action
- map
- map_base_layer
- map_data_mapping
- map_overlay
- menu
- module_grp
- module_item
- msg
- msg_option
- offline_code_file
- platform
- platform_menu
- platform_process_flow
- process
- process_action
- process_action_input_parmtr
- process_action_output_parmtr
- process_action_start_object
- process_flow_schedule_log
- process_step
- process_variable
- reachable_report
- reachable_tab
- reachable_task
- ref
- ref_col
- report
- report_conditional_layout
- report_conditional_layout_condition
- report_parmtr
- report_ref
- report_ref_col
- report_variant
- report_variant_look_up
- report_variant_parmtr
- report_variant_report_conditional_layout
- role
- role_col
- role_cube_field
- role_cube_view
- role_list_bar_grp
- role_list_bar_item
- role_menu
- role_module_grp
- role_module_item
- role_process
- role_process_flow
- role_ref
- role_report
- role_report_parmtr
- role_set
- role_set_role
- role_subroutine
- role_tab
- role_tab_prefilter
- role_tab_report
- role_tab_task
- role_task
- role_task_parmtr
- role_tile
- role_tile_grp
- screen_component
- screen_component_property
- screen_type
- screen_type_breakpoint
- sf_extended_property
- sf_file_storage
- sf_file_storage_extension_whitelist
- sf_oauth_server
- sf_printer
- sf_process_flow
- sf_process_flow_schedule
- subroutine
- subroutine_parmtr
- sync_view
- system_flow_excluded_from_log_clean_up
- tab
- tab_prefilter
- tab_prefilter_col
- tab_report
- tab_report_parmtr
- tab_task
- tab_task_parmtr
- tab_variant
- tab_variant_col
- tab_variant_conditional_layout
- tab_variant_cube
- tab_variant_cube_view
- tab_variant_detail
- tab_variant_look_up
- tab_variant_map
- tab_variant_map_base_layer
- tab_variant_map_data_mapping
- tab_variant_map_overlay
- tab_variant_prefilter
- tab_variant_report
- tab_variant_task
- task
- task_conditional_layout
- task_conditional_layout_condition
- task_parmtr
- task_ref
- task_ref_col
- task_variant
- task_variant_look_up
- task_variant_parmtr
- task_variant_task_conditional_layout
- theme
- tile
- transl
- use_log_usr_action
- usr_audit_filter
- usr_grp_pref_gui_appl
- usr_grp_pref_platform
- usr_grp_pref_start_object
- usr_grp_pref_tab_prefilter_status
- usr_pref_col
- usr_pref_conditional_layout
- usr_pref_conditional_layout_condition
- usr_pref_cube
- usr_pref_cube_view
- usr_pref_cube_view_constant_line
- usr_pref_cube_view_field
- usr_pref_cube_view_field_conditional_layout
- usr_pref_cube_view_field_filter
- usr_pref_cube_view_field_total
- usr_pref_gui_appl
- usr_pref_list_bar_grp
- usr_pref_model_tab_prefilter_status
- usr_pref_module_grp
- usr_pref_platform
- usr_pref_ref
- usr_pref_screen_component
- usr_pref_start_object
- usr_pref_tab
- usr_pref_tab_prefilter
- usr_pref_tab_prefilter_col
- usr_pref_tab_prefilter_status
Changes
| IAM - From table | IAM - From column | IAM - To column | New column - Mandatory | New column - Default value |
|---|---|---|---|---|
| conditional_layout | - | apply_conditional_layout | 1 | 0 |
| gui_appl | - | encrypted_user_name | 0 | NULL |
| gui_appl | - | encrypted_password | 0 | NULL |
| iam_file_storage | - | sas_token | 0 | NULL |
| iam_file_storage | - | use_managed_identity | 0 | NULL |
| iam_file_storage | - | azure_tenant_id | 0 | NULL |
| iam_file_storage | - | azure_client_id | 0 | NULL |
| iam_file_storage | - | azure_client_secret | 0 | NULL |
| map | - | use_custom_label_col_id | 1 | 0 |
| map | - | label_col_id | 0 | NULL |
| ref | - | look_up_display_dom_id | 0 | NULL |
| ref | - | look_up_display_control_id | 0 | NULL |
| ref | - | transl_dom_id | 0 | NULL |
| ref | - | transl_control_id | 0 | NULL |
| report_ref | - | look_up_display_dom_id | 0 | NULL |
| report_ref | - | look_up_display_control_id | 0 | NULL |
| report_ref | - | transl_dom_id | 0 | NULL |
| report_ref | - | transl_control_id | 0 | NULL |
| sf_file_storage | - | sas_token | 0 | NULL |
| sf_file_storage | - | use_managed_identity | 0 | NULL |
| sf_file_storage | - | azure_tenant_id | 0 | NULL |
| sf_file_storage | - | azure_client_id | 0 | NULL |
| sf_file_storage | - | azure_client_secret | 0 | NULL |
| sf_process_flow | api | custom_protocol | - | - |
| sf_process_flow | api_alias | custom_protocol_alias | - | - |
| subroutine | legacy_api | basic_api | - | - |
| tab_variant_conditional_layout | - | apply_conditional_layout | 0 | NULL |
| task_ref | - | look_up_display_dom_id | 0 | NULL |
| task_ref | - | look_up_display_control_id | 0 | NULL |
| task_ref | - | transl_dom_id | 0 | NULL |
| task_ref | - | transl_control_id | 0 | NULL |