2022.2
Support for this release has ended. The release notes are still available for reference, however, no additional updates will be provided. Update to the latest version. See our Lifecycle policy for more information.
We are very excited to announce version 2022.2 of the Thinkwise Platform.
This release contains so many new and improved features! For example, handler procedures for replacing GUI actions, OpenID provider registration and user provisioning, new process flow actions and connectors, improved file storage handling, time zone support, and a lot more.
Here is an overview of everything new, changed, and fixed. Make sure to check out the breaking changes.
New, changed, and fixed in release 2022.2
- Upgrade notes
- Breaking changes
- Software Factory
- New logic concept: handler procedures
- 'Delete' tasks in the Software Factory and IAM replaced by handlers where possible
- Switch file storage location type
- Process flows: changed file and folder connectors
- Process flows: new file and folder connectors
- Process flows: file storage support for SMTP connector
- Process flow action: download file
- Process flow actions: zip and unzip
- Process flow actions: activate scheduler or maps
- Process flow action: send user notification
- Performance: general improvement
- Performance: system flow for tsf_optimize
- Overview of available hotfixes
- Domains: option for standard- instead of user-defined data types
- Deployment: prefilter for failed CI/CD steps
- Creation: separate jobs for 'Connect to database' and 'Execute source code'
- Creation: improved cancel procedure for scheduled jobs
- Creation: improved screen refresh
- Improved status codes for source code execution
- Access control: overview of new, unauthorized objects
- Auto-repeat a task
- Filtered indexes for tables
- Warning for disapproved subname in object names
- Machine learning: estimated training time
- Support for scalar function inlining
- New screen components: task and report tiles
- Menu: hide label in tree view
- New validations
- Renaming printers updates referenced objects
- Projects: revised base projects tab
- Projects: efficient definition generation
- Projects: option added to not grant to public
- Merge generated objects
- Code files now use UTF-8 encoding
- Tasks/subroutines: changed default for atomic transaction checkbox
- Developer mode default for Main administrators
- Import: improved feedback for import error
- Separate synchronization and deployment history
- Messages with audio
- Fixed
- Synchronization to IAM or disk when called from the API
- Extra base/work version check on a Thinkstore content installation
- Improved error messages on failed export to file
- Inactive work status available again
- Generated domains will not be dropped
- Support for Execute source code on empty database
- System versioning disabled when changing table type to view/snapshot/function
- Base project data sensitivity setup included on import
- Saving authorization setup for the Software Factory during an upgrade
- Test administration last run status
- Unit test date parameters
- Renaming control procedure in review
- Reachable objects removed when platform is removed
- Quoted identifiers no longer used for data types that do not allow aliases
- Fixed 'Show at deployment' for code files
- Oracle generation fixes
- Intelligent Application Manager
- Data model changes
Upgrade notes
SQL Server and .NET Framework support
-
The Software Factory development environment and the Intelligent Application Manager require SQL Server 2017 or higher.
Read about the end of SQL Server 2016 support here: https://community.thinkwisesoftware.com/news-updates-21/end-of-sql-server-2016-support-2344
-
This also applies to the Windows and Web user interfaces, which additionally need version 4.7 minimum of the .NET Framework (4.7.2 is advised for Web).
-
The Indicium application tier requires SQL Server 2017 or higher and .NET 5.0. Indicium Basic requires .NET Framework 4.7.2. For more information please check the Indicium documentation.
Breaking changes
File storage for system flows
From now on, the system flows for writing code files, program objects, the manifest, and the IAM synchronization script will use new file storage process flow actions.
This way, it is possible to switch the file storage location type. The files can then be written to, for example, Azure files or AWS S3 storage.
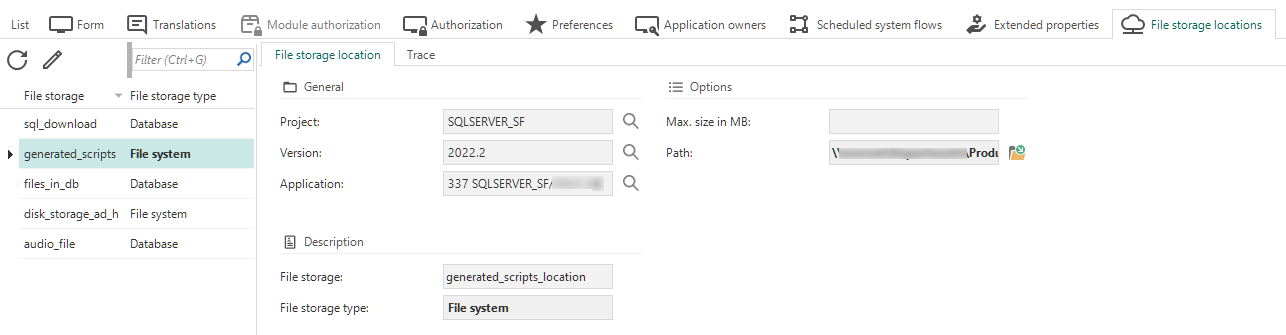
As of this release, you need to set a file storage location for system flows in IAM menu Authorization > Applications.
- Select your SQLSERVER_SF application in tab List and navigate to tab File storage locations.
- In column File storage, select the file storage location
generated_scripts_location. - Edit field Path or change the file storage type using task Switch file storage location type
 .
.
The project folder (as set in the Software Factory > menu Maintenance > Configuration) will no longer be used for the mentioned system flows. It will, from now on, be used only for temporarily storing program objects for the Functionality modeler, project version export (model.dat) files, GUI theme exports, and the Deployer manifest.
 Configure a file storage location for system flows in IAM
Configure a file storage location for system flows in IAM
Icon repository
Community ideaIt is no longer necessary to download and re-upload icons you already used. By introducing the Icon repository, the icons within a project version can now be selected from the central repository.
The repository is available in the menu User interface > Icons. Here, you can add, change, and remove icons. You can check in the available tabs where an icon has been used. This is very useful for impact analysis or for changes directly in the model using the icon as an entry. In addition, you can obtain varbinary literals.
This change has major implications for dynamically assigned icons from code.
As of this version, the following table objects do no longer use icon and icon_data columns, but an icon_id column instead:
- col (Column)
- cube_view (Cube view)
- cube_view_field_conditional_layout (Cube view conditional layout)
- elemnt (Domain elements)
- list_bar_grp (List bar group)
- menu (Menu)
- module_grp (Module group)
- msg_option (Message option)
- process (Custom screens)
- project_vrs (Project version)
- report (Report)
- report_parmtr (Report parameter)
- report_variant (Report variant)
- report_variant_form (Report variant - Form)
- tab (Table)
- tab_prefilter (Table prefilter)
- tab_prefilter_grp (Table prefilter group)
- tab_variant (Table variant)
- tab_variant_form (Table variant - Form)
- task (Task)
- task_parmtr (Task parameter)
- task_variant (Task variant)
- task_variant_form (Task variant - Form)
- tile_grp (Tile group)
After the upgrade to the 2022.2 release, check any dynamic model, control procedure, or custom validation that uses icon fields.
If dynamically assigned icons are used, add them to the icon repository first and then assign their icon identifier (icon_id value) to the objects.
Example code to add icons from dynamic model code to the Icon repository:
-- Insert icons if not already present
insert into icon
(
project_id,
project_vrs_id,
icon,
icon_data
)
select
@project_id,
@project_vrs_id,
v.icon,
v.icon_data
from (values
('customer.svg', [VARBINARY_DATA])
,('message.svg', [VARBINARY_DATA])
,('pencil.svg', [VARBINARY_DATA])
) v(icon, icon_data)
where not exists (select 1
from icon i2
where i2.project_id = @project_id
and i2.project_vrs_id = @project_vrs_id
and i2.icon = v.icon)
![]() Icons in the icon repository
Icons in the icon repository
Improved performance of source code generation
We have improved the source code generation for program objects. Program objects are objects such as triggers or defaults, layouts or handler procedures.
Now, a new field (Code stale, or generated_code_stale) indicates whether the program object's generated code needs to be regenerated or not.
It is set automatically, but its state is visible in the menu Projects > Full model > tab Program objects > group Generation.
- Once code is generated, it is no longer considered 'stale'.
- If the program object is in some way affected, the generated code is set as 'stale' to indicate it needs to be regenerated. For example, in case of new, updated, or deleted assignments, or new, updated, or deleted parameter values.
The result is a better performance since the generated code for program objects no longer needs to be emptied and regenerated upon the project's definition generation unless a part or dependent object has changed. This is checked during the definition generation and code (group) generation. If the program object does not contain any code, it will always be generated.
If you are using the Fully controlled strategy in a Control procedure, you need to explicitly set generated_code_stale to 1 in the code to ensure the
program object's code is regenerated.
It is not necessary to empty prog_object_generated_code.
However, if you are using the Fully controlled strategy in combination with generated_code_stale as described here, using the
Staged
strategy instead is probably more suitable for the Control procedure.
Optimized definition generation
We changed the way in which the definition generation maintains generated objects from base projects in the work project.
- Previously, all (unused) generated objects (like tables, columns, code files, etc.) were deleted and then recreated. As of this release, only the generated objects that no longer exist in any linked base project will be removed. Then, the objects that deviate from objects modified in the base project will be updated, and missing components will be added.
- Moreover, the objects that can be used in a base project were quite limited. This has been expanded, so all project version information is available now, for example, roles, unit tests, variants, AutoML, and cubes.
These optimizations save a lot of IO during generation. Besides, it enables consistent use of generated objects from a base project in the model. For example, by creating a reference to a table from a base project or adding the object to a menu. Previously, this was hardly possible because all generated objects were deleted and recreated.
You can recognize generated objects that are created by a base project by the text "Copied from base project" in group Generation - field By control procedure:

Note that generated objects will be removed only when they are no longer in use.
The use of objects from the base projects will be more uniform from now on. As a result, if a work project has multiple base projects with the same object, the object used may have changed. Previously, the last object (with the highest order no) was used. From now on, the first object (with the lowest order number) is active. In this order, non-generated objects are preferred over generated ones.
A base project for each language
Until this release, the GUI translations base project has always been one large project with the GUI translations of all languages available. Due to the number of available languages growing over time, this base project had also grown exponentially in size. To avoid future problems, we have split the GUI_TRANSL base project into separate base projects per available language.
During the upgrade to the 2022.2 platform, the correct GUI translations base project(s) will be linked automatically to your existing work project in the Software Factory, based on the languages that have been assigned to a project or project version.
As of version 2022.2, an application language in a base project will be copied to the work project. Previously, application languages and their corresponding translations would not be copied to a work project. Translations would only be copied when the application language was already present in the work project. This change may result in the presence of additional application languages after generation. Check the application languages (menu Projects > Project overview > tab Project versions > tab Application languages) in your base projects to resolve this issue.
When you create a new project, the translation base projects will be added based on the default language in the Software Factory configuration. You can add new application languages by linking the corresponding base projects in the menu Projects > Project overview > tab Project version > tab Base projects.
The following GUI translation base projects will be available upon installation of the 2022.2 version of the Software Factory:
- Czech: GUI_TRANSL_CS_CZ
- German: GUI_TRANSL_DE
- English: GUI_TRANSL_ENG
- Spanish: GUI_TRANSL_ES_ES
- French: GUI_TRANSL_FR_FR
- Hungarian: GUI_TRANSL_HU_HU
- Italian: GUI_TRANSL_IT_IT
- Japanese: GUI_TRANSL_JA_JP
- Lithuanian: GUI_TRANSL_LT_LT
- Latvian: GUI_TRANSL_LV_LV
- Dutch: GUI_TRANSL_NL
- Portuguese: GUI_TRANSL_PT_BR
- Romanian: GUI_TRANSL_RO_RO
- Russian: GUI_TRANSL_RU_RU
- Slovak: GUI_TRANSL_SK_SK
- Turkish: GUI_TRANSL_TR_TR
- Chinese: GUI_TRANSL_ZH_CN
Translations for database errors and warnings have been split into base projects per supported database platform, per language. The number of supported languages for these databases is a bit more limited.
Note that adding an application language will not automatically link base projects containing GUI- or database message translations for this language. You can link one of these separate base projects to your project or create a new one for another language.
- DB2_MSG_TRANSL_ENG
- DB2_MSG_TRANSL_NL
- DB2_MSG_TRANSL_DE
- ORACLE_MSG_TRANSL_ENG
- ORACLE_MSG_TRANSL_NL
- ORACLE_MSG_TRANSL_DE
- SQLSERVER_MSG_TRANSL_ENG
- SQLSERVER_MSG_TRANSL_NL
- SQLSERVER_MSG_TRANSL_DE
The SCREEN_TYPES base project no longer contains application languages but will provide a new work project with default translations for screen types and tab controls in English, German and Dutch.
OpenID provider registration and user provisioning
Community ideaAs of this release, you can register multiple external identity providers and enable provisioning for these providers in IAM. All settings for external identity providers and provisioning are available in IAM, in menu Authorization > OpenID providers. These settings replace the OpenID configuration in Indicium's appsettings.json.
It was already possible in IAM to configure external OpenID clients, thus using the Thinkwise Platform as an OpenID provider.
- Remove the OpenID configuration from the appsettings.json.
- Deploy Indicium again.
- Upgrade IAM.
- Add the OpenID settings (menu Authorization > OpenID providers).
- In column Identity provider, use the same name as previously in the reply URL in the appsettings.json (
<indicium_url>/signin-<openid_provider_id_in_iam>). - If, in the appsettings.json,
"UserIdClaimType"had a value, use the same value in field Identifying claim in IAM. - For more information, see the OpenID Connect manual.
- In column Identity provider, use the same name as previously in the reply URL in the appsettings.json (
When registering an OpenID provider, it is possible to enable provisioning. In that case, users will be created and updated in IAM after authentication, based on the claim values received from the OpenID provider. If you configure user groups, they will also be automatically created or updated for the user.
You can set up a template for automated provisioning, manually modify requested scopes, and update mappable claims. Scopes allow you to request specific information about users. Claims are bits of information about the user that become available when certain scopes are requested.
Some values in IAM ('categorical values') are unlikely to be included in the same format in the OpenID providers' claims. For these values, you can provide a mapping.
A log is available for OpenID providers, showing all login attempts and providing extra information about any provisioning.
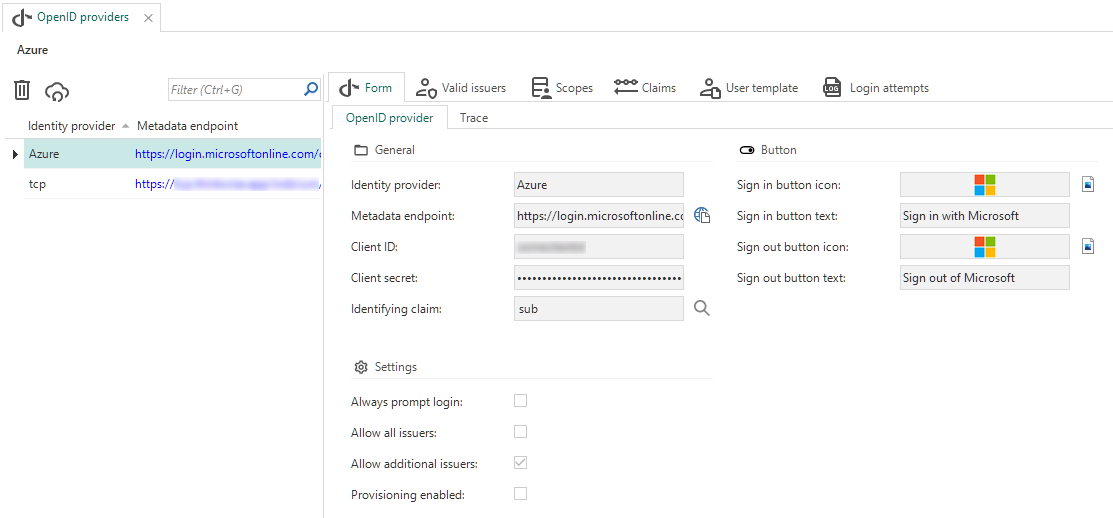 OpenID settings in IAM
OpenID settings in IAM
Oracle projects: changed length usage and support for session variables
For Oracle projects, we have solved a potential discrepancy between the expected maximum input length in the database and the runtime components.
We have updated the generation process to force the usage of another data type (CHAR) to define the input length when tables are created or upgraded. Existing domains are kept as-is, but any modification to a domain will apply the CHAR length indicator. As a result, the tables using this domain will be marked for upgrade. To force this change and generate an upgrade script to have it take effect in the product database, you need to do a quick update of all VARCHAR2 and CHAR domains (toggle the domain's control type, for example).
Furthermore, a new procedure (tsf_set_session_variable) has been added to the generation process of Oracle databases to support the use of session variables by Indicium for Oracle. This procedure needs to be applied at least once after the upgrade to 2022.2.
Software Factory
New logic concept: handler procedures
Community ideaA highly requested functionality has come available: you can now replace the insert, update and delete GUI actions by handler procedures.
This new logic concept allows you to override the default insert, update and delete SQL commands initiated by the user interface and Indicium with your own business logic. It can be used best for actions that need to be performed row-by-row. Some examples are:
- Deleting child records before deleting a parent record
- Hiding
deletedrows for users instead of removing them. To achieve this, you could use a hiddendeprecatedfield with a prefilter. When a row is 'deleted', this field will be updated to1, and the row will be hidden). - Updating a reference field with a changed customer name.
For set-based actions, it is best to use triggers.
The handler procedures are atomic by default, which means all code is run inside a transaction. This ensures that all mutations will be either run successfully in their entirety or fail and roll back to their original state.
Like other logic concepts, you can (de)activate the handler logic per table and action (menu User interface > Subjects > tab Default > tab Settings > tab Performance):
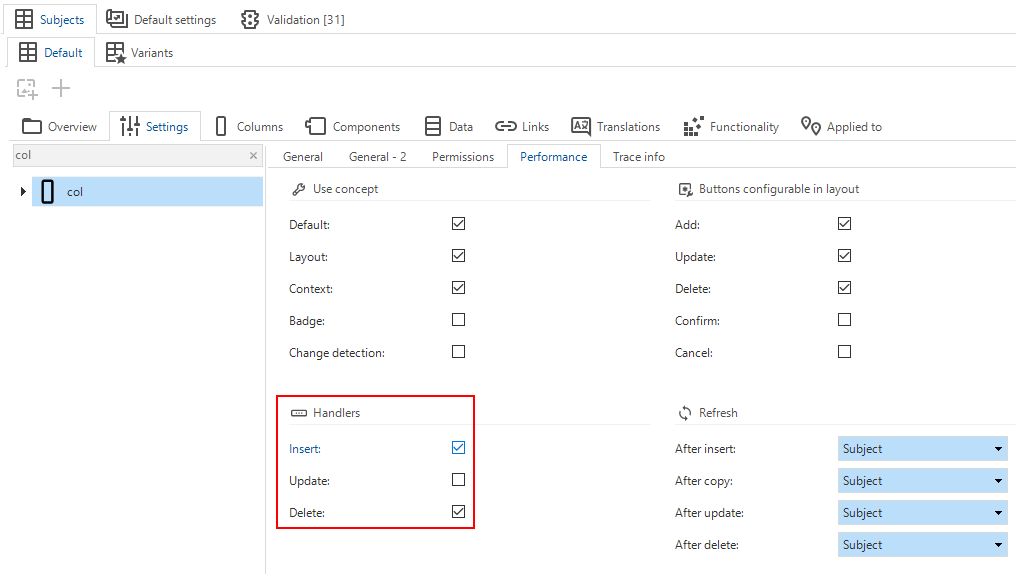 Activate the handlers
Activate the handlers
In Functionality (menu Business logic), you have to assign code group HANDLERS to the control procedure. Then, you can assign the templates.
The stored procedures for handlers can be unit-tested.
'Delete' tasks in the Software Factory and IAM replaced by handlers where possible
At several locations in the Software Factory and IAM, a separate delete task was available that allowed you to delete the selected record(s), including all of
its underlying data. This task has been replaced by a handler where possible.
As a result, you can now delete a record and its underlying data simply by executing the delete ![]() action from the CRUD actions.
This change only applies to the delete tasks for the immediate corresponding subject, such as delete table for tables, delete column for columns, etc.
action from the CRUD actions.
This change only applies to the delete tasks for the immediate corresponding subject, such as delete table for tables, delete column for columns, etc.
![]() 'Delete' in the CRUD actions
'Delete' in the CRUD actions
If a form (and therefore the CRUD action) is not available or visible, you can still delete a record using the ribbon, context menu, or keyboard shortcut.
 'Delete' in the context menu
'Delete' in the context menu
Delete tasks ![]() in a different context are still available since these cannot be replaced by a handler.
For example, in menu Specification > Business processes, the same delete task is still used for deleting either a requirement, business process,
or work item, or in the menu User interface > Menus > tab Design, the same delete task is used for deleting a tree group or a tree group item.
in a different context are still available since these cannot be replaced by a handler.
For example, in menu Specification > Business processes, the same delete task is still used for deleting either a requirement, business process,
or work item, or in the menu User interface > Menus > tab Design, the same delete task is used for deleting a tree group or a tree group item.
Switch file storage location type
It is now possible to deviate from the initially configurated file storage location type. For example, the Software Factory writes its code files to disk (default) but this can be switched to AWS. Then, if a system flow contains a Write file connector using the reconfigured file storage, Indicium would write it to AWS S3. This is available for file storage locations for applications in IAM and runtime configurations in the Software Factory.
Note that file storage locations cannot be switched from or to storage type "Database".
The initial file storage location for a project version is set in the menu Projects > Project overview > tab Project version > tab File storage locations.
-
In IAM, you can override the file storage location in the menu Authorization > Applications > tab File storage locations > task Switch file storage location type
.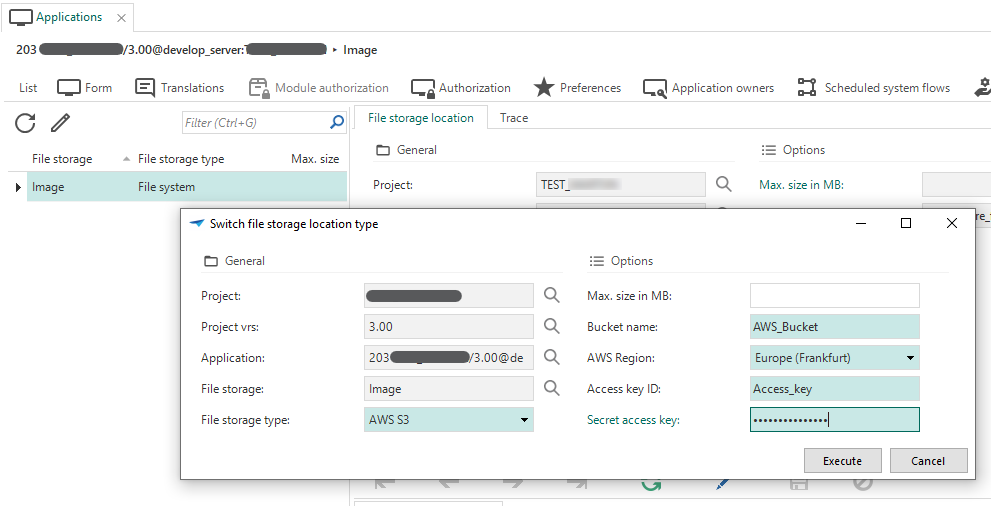 Switch to another file storage location in IAM
Switch to another file storage location in IAM -
In the Software Factory, you can configure the file storage location for each runtime configurations in the menu Maintenance > Runtime configurations > tab File storage locations > task Switch file storage location type
.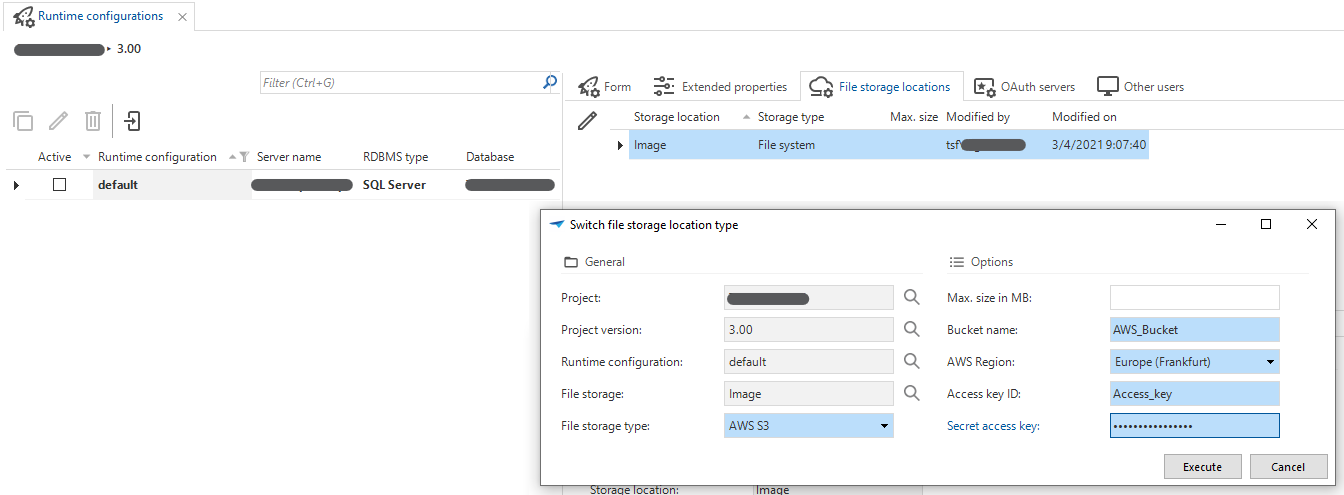 Switch to another file storage location for the runtime configurations in the Software Factory
Switch to another file storage location for the runtime configurations in the Software Factory
Process flows: changed file and folder connectors
In this release, the existing file- and folder connectors for process flows have been renewed and extended. The reason is the change from ad-hoc disk connectors to file storage-based connectors.
To keep the two apart, the old connectors have been renamed and moved to the bottom of the list of available process flow connectors. They should no longer be used if they are not necessarily required. We have added an information-level validation to alert you if old ad-hoc disk connectors are still in use. We strongly advice using the file-storage based connectors.
The old ad-hoc disk connectors have been renamed as follows:
| Old name | New name |
|---|---|
| Copy file | Copy disk file (non-file storage) |
| Copy folder | Copy disk folder (non-file storage) |
| Create folder | Create disk folder (non-file storage) |
| Delete file | Delete disk file (non-file storage) |
| Delete folder | Delete disk file folder (non-file storage) |
| Move file | Move disk file (non-file storage) |
| Move folder | Move disk folder (non-file storage) |
| Read file | Read disk file (non-file storage) |
| Write file | Write disk file (non-file storage) |
| FTP connector | FTP connector (non-file storage) |
Thus, renaming the ad-hoc disk connectors has made room for adding new file storage-based connectors:
| New file connector | Description |
|---|---|
| Copy file | Replaces the old ad-hoc Copy file connector. It allows copying files within a storage location. If you select this connector, it is mandatory to select the storage location. To copy between file storage locations, use the Read file and Write file connectors. |
| Copy folder | Replaces the old ad-hoc Copy folder connector. It allows copying folders within a storage location. If you select this connector, it is mandatory to select the storage location. To copy folders between file storage locations, use the Create folder, Read file and Write file connectors. Use List folder to retrieve the contents of the folder. |
| Delete file | Replaces the old ad-hoc Delete file connector. It allows deleting files from a storage location. If you select this connector, it is mandatory to select the storage location. |
| Delete folder | Replaces the old ad-hoc Delete folder connector. It allows deleting folders from a storage location. If you select this connector, it is mandatory to select the storage location. |
| Move file | Replaces the old ad-hoc Move file connector. It allows moving files from one storage location to another. If you select this connector, it is mandatory to select the target storage location. |
| Move folder | Replaces the old ad-hoc Move folder connector. It allows moving folders from one storage location to another. If you select this connector, it is mandatory to select the target storage location. |
| Read file | Replaces the old ad-hoc Read file connector. It allows reading files from a storage location. If you select this connector, it is mandatory to select the target storage location. |
| Write file | Replaces the old ad-hoc Write file connector. It allows writing files to a storage location. If you select this connector, it is mandatory to select the target storage location. A new input parameter has been added: Write preamble. It tells Indicium it should write a preamble for the code file. A preamble (also known as Byte Order Mark, or BOM) consists of some bytes at the start of a file. They indicate how the text has been stored binarily (in which coding). Not all encodings contain a preamble. |
Process flows: new file and folder connectors
In addition to replacing the old file and folder connectors, we have created two new connectors with file storage support:
- List folder - Allows returning the contents of a folder in a list. If you select this connector, it is mandatory to select the target storage location. This connector can be used in combination with the new zip and unzip process actions.
- Print file - Allows printing PDF-files from a storage location. If you select this connector, it is mandatory to select a printer.
Process flows: file storage support for SMTP connector
In addition to the new file and folder connectors, the SMTP connector now also supports file storage to store attachments. So, if you select 'SMTP connector' as a Process action type, it is possible to select a Storage location.
If you have selected a storage location and wish to make attachments available, you need to add a path to input parameter Storage attachment path. You can add one absolute path to a file in the file storage location that contains the email attachments.
Three new status codes have been added to support working with file storage:
- -6 - No storage configuration was configured.
- -7 - The storage attachments path input parameter was given an invalid value, it must be a valid, absolute path.
- -8 - The storage attachments path input parameter refers to a file that does not exist, or a folder instead of a file.
For backward compatibility, it is still possible to use the SMTP connector without a file storage location. The corresponding parameters for attachments are still available, but have been renamed to Disk file attachments and Disk file deletable attachments.
Process flow action: download file
In addition to the new file and folder connectors, a new process action is available: Download file.
You can set process variables and use them in the input parameters to make a file available for download to the end-user. The file can originate, for example, from a database, or from file storage using a Read file connector, or it can be the result of a Generate report connector.
Process flow actions: zip and unzip
Community ideaWe have created some highly requested process flow actions: zipping and unzipping files and folders.
- Zip file takes a pointer to either a file or folder within the selected file storage location. Indicium will zip the file or folder and return the file data as output, plus a JSON-formatted string with the contents of the zipped file or folder.
- Unzip file takes both the zip file name and the file data to unzip the given file and folder data and creates a given folder name to put in the content. The output will return the unzipped file paths in JSON format.
 Process actions for zipping and unzipping files
Process actions for zipping and unzipping files
Process flow actions: activate scheduler or maps
Windows GUI Web GUIIt is now also possible to activate the Scheduler and Maps components via process flows, using new process actions:
- Activate scheduler allows users to navigate to a specific date and time inside the scheduler.
- Activate maps allows users to open the Maps component and zoom in on a specific coordinate.
 Process actions for activating Maps or the Scheduler
Process actions for activating Maps or the Scheduler
Process flow action: send user notification
Universal GUI Community ideaWe have added a new process action as a first step towards supporting notifications. It is called Send user notification, and you can use it for push notifications to users.
Three input parameters are available: User ID, Notification text, and Expiry date-time (UTC). Indicium uses these data to send the notification text to the specified user as soon as they are logged in. You can use the Expiry date-time to stop the notifications from popping up after a specified time.
In IAM, you can send notifications without a system flow in the menu Analysis > Notifications > tab Notifications.
In the same tab, pending notifications are visible for both types. You can set the number of expired or sent notifications that should remain visible in menu Settings > Global settings > group User > field Notification retention (items).
 A process action for sending a user notification
A process action for sending a user notification
Performance: general improvement
Many generation-related subroutines have been improved by leveraging the SQL 2016 string_split function, reducing CPU pressure on the Software Factory database.
Performance: system flow for tsf_optimize
Community ideaThe Software Factory (sqlserver_sf) application in the Intelligent Application Manager (IAM) now has a system flow called system_flow_run_tsf_optimize.
It will run the tsf_optimize procedure according to its active custom schedule.
By default, this system flow does not come with a schedule.
If you would like to use one, first disable the prefilter Active ![]() in the Scheduled system flows tab to make
the system flow visible (in IAM, menu Authorization > Applications > tab Scheduled system flows).
Then select the system flow and create a custom schedule.
In tab Schedule, activate
in the Scheduled system flows tab to make
the system flow visible (in IAM, menu Authorization > Applications > tab Scheduled system flows).
Then select the system flow and create a custom schedule.
In tab Schedule, activate ![]() your schedule to let Indicium run this system flow at the indicated intervals.
your schedule to let Indicium run this system flow at the indicated intervals.
tsf_optimize is a procedure inside the SQLSERVER_DB base project.
It can speed up the performance of SQL Server when many indexes are fragmented and statistics outdated. Running this procedure does two things:
- It collects all indexes of the database that have an average fragmentation of 15% or higher and over 1000 pages. Each index will be reorganized if the fragmentation is lower than 30% to use minimal system resources. If the fragmentation is 30% or higher, the index will be rebuilt.
- It collects all statistics of all user-created tables that have been modified at least once. These collected statistics will then be updated using FULLSCAN.
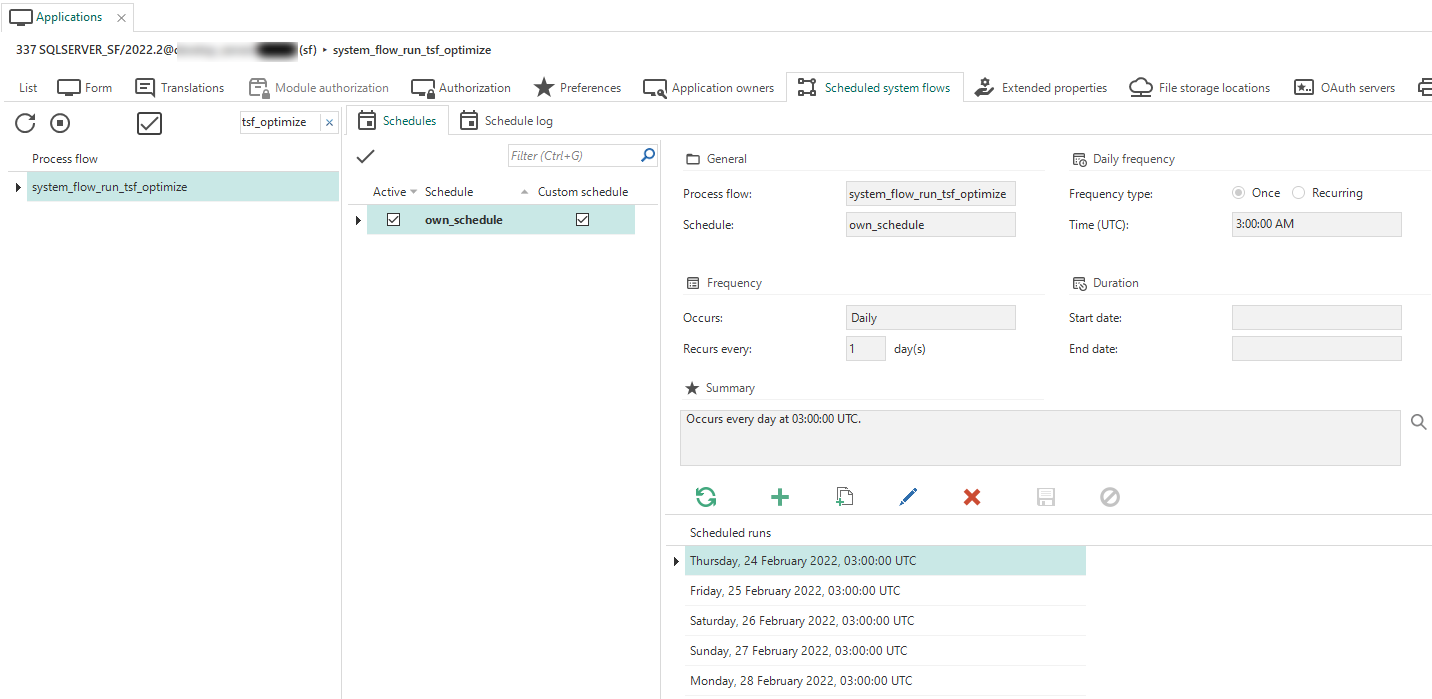 A schedule for the tsf_optimize system flow
A schedule for the tsf_optimize system flow
Overview of available hotfixes
Community ideaWe built a new service that returns an overview of all available hotfixes for the Software Factory and Intelligent Application Manager. A system flow updates the hotfix table to see if new hotfixes are available for download in TCP.
- In the Software Factory, available hotfixes are visible in the menu Maintenance > Hotfixes.
- In IAM, this overview is available in the menu Settings > Hotfixes.
Domains: option for standard- instead of user-defined data types
Community ideaWe have added a Use domains option to the project version screen (menu Projects > Project overview > tab Project versions > tab Form). This option is enabled by default. When it is disabled, all tables will use standard data types instead of the user-defined data types for the domains.
It should be used when, for example, you wish to use SQL Data Sync to synchronize data between Azure databases since this tool cannot process user-defined data types.
If you change this option, all tables need to be rebuilt. They will automatically be set to 'changed' and added to the data conversion (and therefore to the upgrade script).
Deployment: prefilter for failed CI/CD steps
When one of the steps in the Deployment process has failed, you can now use the prefilter Status 'Failed'. It will save you scrolling through the long list of steps to see which one has failed. It is available on the following screens, in the Start ribbon under Prefilters:
- menu Deployment > Creation > tab Generate definition > tab Generation steps > select one of the generated steps.
- menu Deployment > Creation > tab Generate source code > select one of the generated steps.
- menu Deployment > Synchronization to IAM > select one of the generated steps.
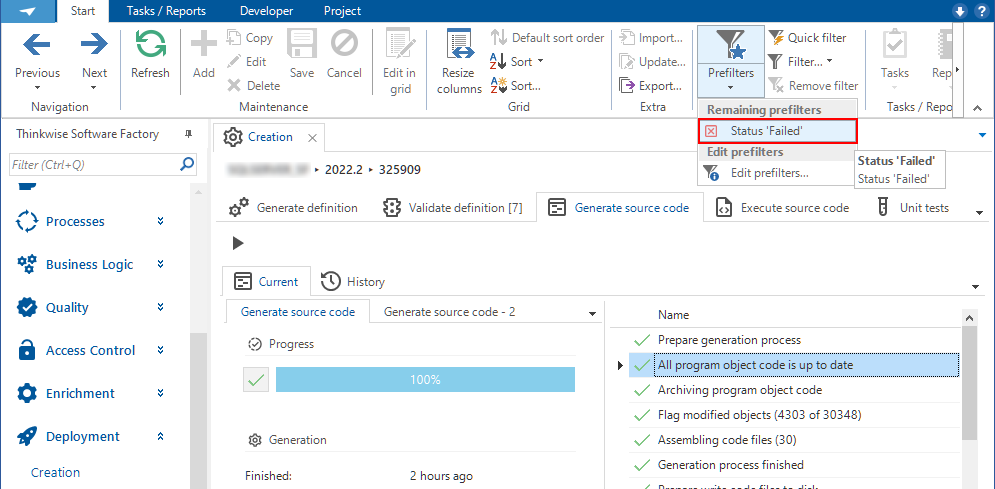 A prefilter for failed deployment steps
A prefilter for failed deployment steps
Creation: separate jobs for 'Connect to database' and 'Execute source code'
In the Creation process (menu Deployment > Creation), we have redesigned the system flow for executing source code.
Connecting to the database is now a separate job and will no longer keep a job running in the background. This makes it possible to select and execute code files in the Execute source code screen until a new Generate definition or Source code job has been started for the project version, or a timeout of 5 minutes has been reached. In that case, the connection needs to be renewed.
The connection can also be closed using the new Close database connection task ![]() that will appear once an open
connection is detected.
that will appear once an open
connection is detected.
Creation: improved cancel procedure for scheduled jobs
Previously, when two sets of jobs within the Creation process were scheduled to be executed consecutively, the second job would be canceled if the first job failed, even if no dependency existed between them. This has been changed. So if, for example, Execute source code fails, a scheduled Generate definition job will run as planned.
Creation: improved screen refresh
We have added more moments when the screens refresh in the Creation and Synchronization to IAM processes (menu Deployment):
- The Validate definition screen now also refreshes after the definition has been generated, to show new validations and current validation statuses.
- The Execute source code screen now also refreshes after the definition has been generated, to indicate the absence of executable code files.
- The Execute source code screen now also refreshes after the source code has been generated, to indicate the presence of executable code files.
- All creation and synchronization screens now also refresh after Indicium has recovered from downtime. This will clear the message that the agent is currently not running.
Improved status codes for source code execution
Indicium will now return different status codes depending on the type of error that occurred when connecting to a database. This offers more accurate error messages when you try to connect to a database to execute source code, which makes it possible to apply a more specific error handling.
Access control: overview of new, unauthorized objects
Community ideaWhen modelling a project in the Software Factory, you create new objects, such as tables, columns, and tasks. The next step should be to assign the correct authorization to those objects. This step might be forgotten, though. In that case, without the proper authorization, users cannot see or interact with the newly created object.
To offer you a better insight into which new objects have not been authorized yet, we have expanded the overview on the New objects tab
(menu Access control > Model rights).
Here, you can manually check whether a role has been assigned to each new object.
If so, you can declare that its authorization has been verified by executing the Mark as verified ![]() task.
Information on whether an object has been verified, by whom, and when is added to the form.
task.
Information on whether an object has been verified, by whom, and when is added to the form.
Initially, the grid will only show the new objects that have not been verified yet.
You can display all verified new objects by disabling the Unverified objects ![]() prefilter.
prefilter.
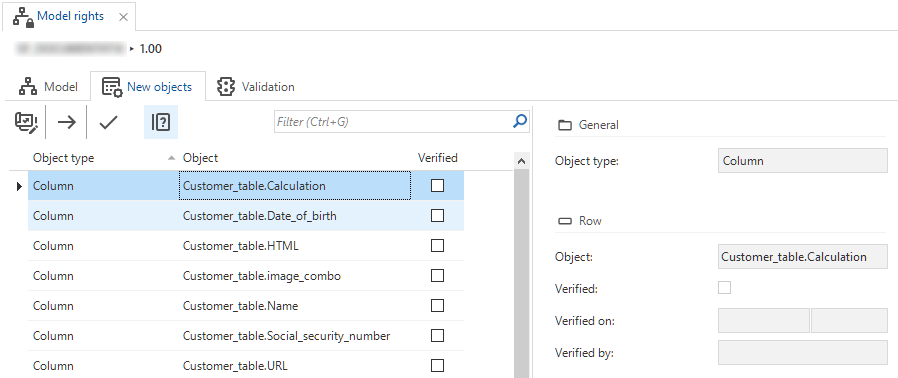 Overview of new, unauthorized objects
Overview of new, unauthorized objects
Auto-repeat a task
To improve working with external tools that interact with your application, it is now possible to repeat tasks after execution. A new checkbox is available, in menu Processes > Tasks > tab Default/Variants > tab Settings > tab General > group User interface > checkbox Repeat after execute.
If you select this checkbox, the task pop-up will automatically open up again after executing the task. Cancelling the task pop-up will end this cycle.
This is a useful setting for, for example, using barcode scanners and executing tasks after scanning a product. By repeating the task, a user can continue scanning products without the need to reopen the task pop-up manually.
Filtered indexes for tables
Community ideaIndexes can now be created with a Where clause. This, for instance, can be beneficial for performance when only active records need to have an index.
An index for a table is created in menu Data > Data model > tab Tables > tab Indexes.
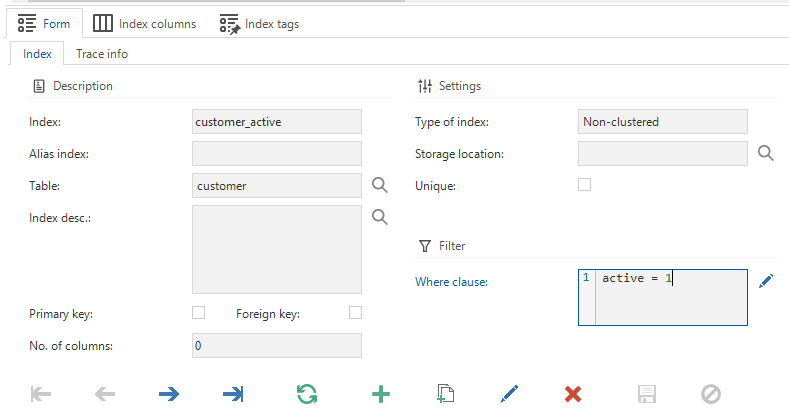 An index with a Where clause
An index with a Where clause
Warning for disapproved subname in object names
When you create a new object, such as a column, you must give it a name. This name may contain previously disapproved subnames. You will now receive a warning if this happens. The same warning is displayed if you copy or rename objects and specify disapproved subnames in the process.
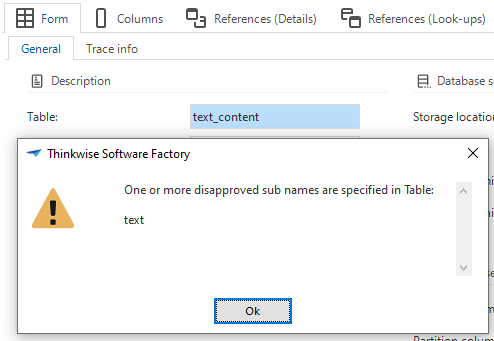 Example warning for a disapproved subname in an object name
Example warning for a disapproved subname in an object name
Machine learning: estimated training time
Machine learning can now estimate the time it will probably take for a model to train.
After loading training data and obtaining result models, a wall-clock time prediction in minutes will be shown. For every model type, the estimated training time will be calculated. The calculation is based on the training data, the given targets, and predictors. Until the training starts, you can select or deselect models.
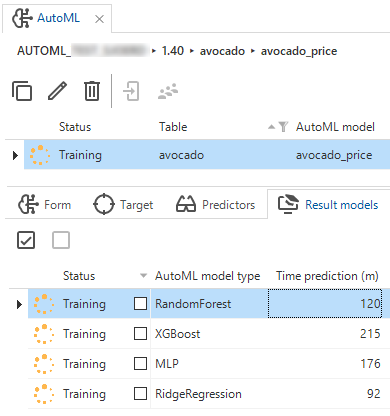 Predicted time
Predicted time
Support for scalar function inlining
You can now mark SQL Server scalar functions inlineable using a subroutine option. This feature of SQL Server can considerably speed up queries that use the function.
When a scalar function is marked inlineable, the generated function header will no longer use user-defined datatypes.
Instead, it will use the 'raw' datatypes of the domains.
The script to create the function will use the INLINE = ON clause to force it to become inlineable.
Note that there are
restrictions
to keep in mind when writing logic for an inlinable function.
This option is available in the menu Business logic > Subroutines > tab Default/Validation > tab Subroutine options.
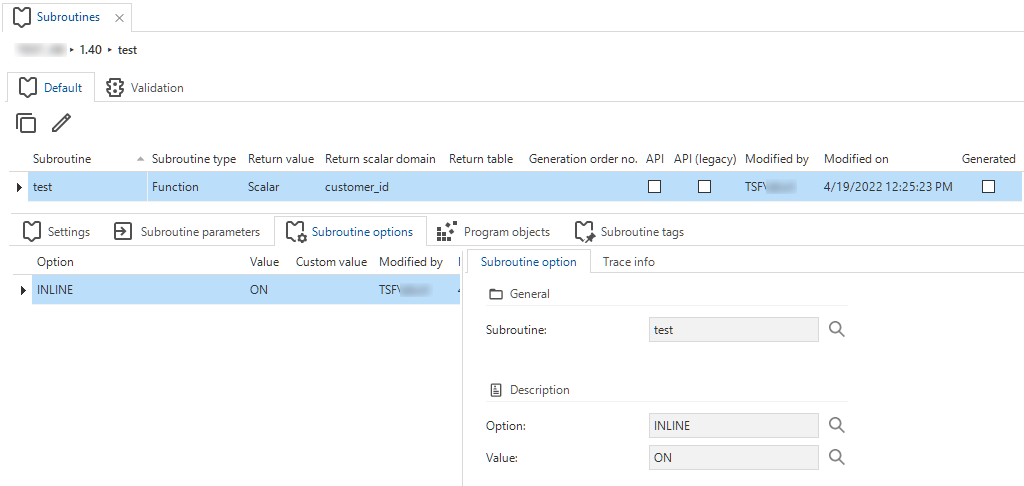 INLINE option for a scalar function
INLINE option for a scalar function
New screen components: task and report tiles
Soon available for Universal GUI Community ideaTwo new screen components are available. Both are similar to the Detail tiles component.
- Task tiles - Displays all tasks assigned to the subject as tiles.
- Report tiles - Displays reports assigned to the subject as tiles.
 Tasks displayed as tiles
Tasks displayed as tiles
Menu: hide label in tree view
Community ideaIn a tree view, when you use a tree based on a group column, the column label was always visible on top of the grouped column value. As a result, the row took up double the space, even though it is not always required to show the label.
It is now possible to hide the label from the tree view, with the new option called Show label. It is available in the menu User interface > Subjects > Settings. This option is disabled by default. So, the label will be hidden by default. If you wish to show the label in the GUI, you should enable it.
New validations
-
Change detection active without auto refresh- An info validation to check for tables where Change detection is active without auto-refresh for the table or its variants. This will have no effect when working in a GUI. However, this setup does suffice when calling the change detection logic directly via the API. You can change the setup or approve the validation message. -
System version table contains calculated field (function)- A validation to check if a system version table contains a calculated field (function). The calculated field (function) performs user or system data access or is assumed to perform access. Since this is not allowed, the table cannot be applied correctly to the database. -
Unique index is equal to the full primary key- A check for foreign key constraints that may introduce dependencies on this unique index, making it difficult to delete or re-apply. It will also result in errors during full code execution.
Renaming printers updates referenced objects
Since printers were not inside the context of project versions, renaming a printer did not affect objects using this printer. This has been changed.
Printers is now a new tab in menu Projects > Project overview > tab Project versions. It is no longer available in menu Advanced > Hardware.
Projects: revised base projects tab
Since the number of available Thinkwise base projects is increasing vastly, we have revised the Base projects tab (Projects > Project overview > Project versions > Base projects). It now contains a list (instead of a list and form), possibilities for selecting and deselecting, and a filter for linked base projects. This makes it easier to choose the correct base project.
After linking ![]() one or more base projects,
you will be asked to directly schedule the work project's definition generation.
It is also possible to manually
one or more base projects,
you will be asked to directly schedule the work project's definition generation.
It is also possible to manually ![]() generate the definitions later.
Definition generation is required to retrieve the objects from the base project into the work project.
generate the definitions later.
Definition generation is required to retrieve the objects from the base project into the work project.
As of version 2022.2, you can no longer link multiple versions of a base project to a single work project version. Instead, you can only link one version of a base project to one version of a work project. Additional links will be removed during the upgrade to 2022.2. You will be informed by an upgrade validation message.
Projects: efficient definition generation
Previously, when you created a new project or added a base project to an existing work project, you had to navigate to the Creation menu and manually generate the definition there. This has been improved, resulting in the following changes:
- If you create a brand new project, a job will be scheduled automatically to have its definition generated. You can view this job in menu Maintenance > Jobs.
- If you link
 or unlink
or unlink  a new base project, a message is displayed requesting
if you wish to generate the definition (menu Projects > Project overview > tab Project versions > tab Base projects).
a new base project, a message is displayed requesting
if you wish to generate the definition (menu Projects > Project overview > tab Project versions > tab Base projects). - If you do not generate the definition immediately after (un)linking a base project, you can schedule the job manually by executing the Generate definition
task
 (menu Projects > Project overview > tab Project versions > tab Base projects).
Executing this task is optional, but it saves opening the Creation menu and generating the definition there.
(menu Projects > Project overview > tab Project versions > tab Base projects).
Executing this task is optional, but it saves opening the Creation menu and generating the definition there.
Projects: option added to not grant to public
Community ideaA new tag has been introduced to modify whether a grant .. on .. public will be added at the end of procedures such as creating tables or stored procedures.
This line affects database authorization for functionality and upgrades.
When you add the tag NO_GRANT_TO_PUBLIC to a specific project, this line will no longer be added to any procedure within the context of the project. Note that you need to generate the project's definition after adding the tag.
You can add the tag to the Software Factory's Advanced menu > Projects > tab Project tags. If added here, it will be applied to your entire project.
 New project tag: NO_GRANT_TO_PUBLIC
New project tag: NO_GRANT_TO_PUBLIC
Merge generated objects
The Software Factory now takes generated objects into account when merging a branch.
Until platform version 2022.1, generated objects would be excluded from the base versions and (temporarily) removed from the project while performing the difference analysis. Initially used as a performance boost to prevent delta actions based on model objects imported from base projects, this is no longer necessary due to the persistent nature of generated objects in version 2022.2.
This change also resolves various issues with generated objects becoming used or unused in a branch or trunk. The difference analysis would not pick up these changes or misinterpret them as an insert or delete.
Any branch created in version 2022.1 or earlier will not contain generated objects in the base version. A merge session for these branches performed in 2022.2 will flag the generated objects in the latest branch- and trunk version as 'inserted'.
This may potentially be thousands of delta actions. Generated objects such as control procedures, templates, validations, and translation objects from base projects will be marked as 'inserted' in the branch and the trunk. These objects should be the same in the branch and trunk, and all conflicts will automatically be resolved. This will, however, result in a much slower merge compared to the merge of future branches created with platform version 2022.2.
Code files now use UTF-8 encoding
Code files will now be written with UTF-8 encoding instead of ANSI Latin1 (Windows-1252). In combination with the Thinkwise Deployment Center, this will ensure that code files containing non-Latin characters will be deployed correctly.
Tasks/subroutines: changed default for atomic transaction checkbox
Community ideaWhen setting up new tasks or subroutines, the default value of the Atomic transaction setting used to be 'false'. Now, it will be set to 'true' by default if the project does not yet contain any tasks or subroutines or when it has been set to 'true' in the majority of the existing tasks or subroutines. If the Atomic transaction setting has not been set to 'true' in the majority of the existing tasks or subroutines, the default value will remain 'false'.
The setting Atomic transaction is available as a checkbox in the menus:
- Business logic > Subroutines > tab Settings > tab Subroutine.
- Processes > Tasks > tab Settings > tab General.
Developer mode default for Main administrators
For Main administrators, developer mode is now enabled by default. Therefore, it is no longer required to configure developer mode in IAM for a Main administrator.
Developer mode offers extra options in the Developer ribbon.
Import: improved feedback for import error
While importing a project version, an error can occur if base data is present in the imported project version but not in the Software Factory. This error was quite technical and, therefore, hard to understand. We have improved this. One example is: "Programming language used in table "Project version" is not present in table "Programming language"."
Separate synchronization and deployment history
Synchronization history and Deployment history now both have their own menu item in the Software Factory's Advanced menu > Log. Previously, both were available in menu item Synchronization history.
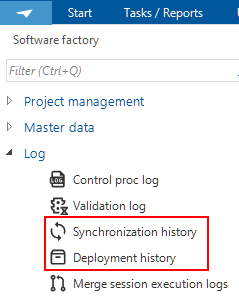 Seperate menu items for synchronization and deployment history
Seperate menu items for synchronization and deployment history
Messages with audio
Windows GUIMessages can now play audio. For each message, you can upload an audio file in the menu User interface > Messages > tab Form. The audio file will be played upon receiving the message. The allowed extensions are .wav and .mp3.
Fixed
Synchronization to IAM or disk when called from the API
If synchronization to IAM or disk was started through the API, the screen would not refresh properly and show running jobs. This has been fixed.
Extra base/work version check on a Thinkstore content installation
When you install Thinkstore content into an existing project version, the pop-up will no longer automatically select a base project when the entered new project ID matches a base project and if the content is a work project. This rule applies to, for example, a re-installation or a new version release.
In reverse, the pop-up will no longer automatically select a work project when the entered new project ID matches a work project and if the content is a base project.
In both situations, this would result in an empty combo box. An error will be shown if a project is executed with a new ID that already exists as a work- or base project.
Improved error messages on failed export to file
If a project version's export file cannot be written to the file location within the project folder, the Software Factory will no longer show a generic error message. Instead, details regarding the error will be provided. For instance, if access is refused or the file is in use. This makes it easier to solve the problem.
Inactive work status available again
It is now possible again to choose an inactive work status for a work item.
Generated domains will not be dropped
Generated domains will no longer be dropped when they are used by process variables.
Support for Execute source code on empty database
When working with, for example, Azure, empty databases are often created before the Execute source code process.
This process now does an additional check to see if the sf_product_info table exists.
If it is missing, it means the end product database has not been fully created yet, and the Create code file will be marked for execution.
System versioning disabled when changing table type to view/snapshot/function
When changing the Table type from Table to View, Snapshot, or Function, system versioning will now be disabled.
Base project data sensitivity setup included on import
Previously, when importing a base project into a work project, the data sensitivity column setup did not migrate properly. Neither could the setup be changed in the work project because then it would be overwritten by the base project. Now, any column sensitivity setup in the base project will be included when importing that base project into a work project.
Saving authorization setup for the Software Factory during an upgrade
Previously, when upgrading the Software Factory from one version to the next, the setup of the user groups and their roles would be lost when the user groups were not part of the default tenant in IAM. Now, the authorization setup is copied from the previous Software Factory version to the application in the new version, regardless of the tenant.
Test administration last run status
We fixed an issue where the last run status of the test scenario would not change to 'failed' when it failed.
Unit test date parameters
Unit test parameters with a DATE domain will now be returned as DATE instead of DATETIME.
Renaming control procedure in review
Previously, when renaming a control procedure that was still under review, an error would arise. This error has been fixed, making it possible to rename a control procedure regardless of its status.
Reachable objects removed when platform is removed
Previously, when a platform was deleted from a project version, the underlying reachable objects would remain intact if the Investigate reachable objects task was not executed. Now, they will be deleted accordingly.
Quoted identifiers no longer used for data types that do not allow aliases
Some data types, such as FILESTREAM, UNIQUEIDENTIFIER, etc., do not support quoted identifiers. Therefore, these data types will no longer allow aliases.
Fixed 'Show at deployment' for code files
As of the 2021.3 release, the setting Show at deployment was no longer honored when deploying code files. In this 2022.2 release, the code files are no longer shown when deploying your end-product if this setting is disabled. It is available in menu Projects > Full model > tab Code files.
Oracle generation fixes
- Generation of process logic package headers could leave the header in missing parameters during the first generation cycle. This has been fixed.
- Process logic naming will no longer force the use of model casing via quoted identifiers. It will now use an unquoted identifier, which Oracle defaults to uppercase.
- We have solved that creating data migration scripts could result in missing source table ids in some situations.
Intelligent Application Manager
Time zone information setting for users
It is now possible to set a time zone for a user. The time zone for a new user will be set to 'etc/UTC' by default but can be changed in IAM, in menu Authorization > Users > tab Form > tab User > group User preferences > field Time zone. It is also possible to add time zone claim mappings for users through OpenID Connect provisioning.
Universal GUI Community ideaWhen you select a control for a domain that shows a DateTime value, you can choose whether it should display the time for the user's current time zone or as stored in the database (Software Factory > menu Data > Domains > tab Form).
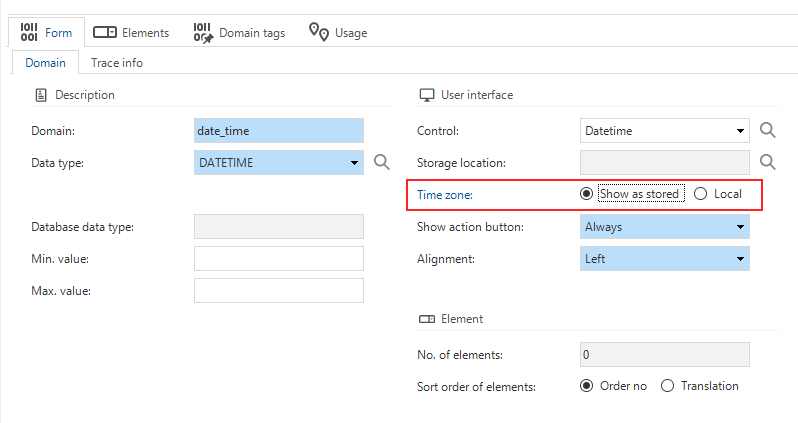 Timezone in a domain
Timezone in a domain
PKCE for OpenID clients
For OpenID clients configured in IAM, you can now set that PKCE (Proof of Key for Code Exchange) is required. This is a mechanism to make the use of OAuth 2.0 Authorization Code grant type more secure in certain cases.
After the upgrade, this option is enabled by default for new OpenID clients. For existing OpenID clients, it will remain disabled. The setting is available in menu OpenID > OpenID clients > tab OpenID client > group General > checkbox Require PKCE.
Translations for login
Community ideaIt is now possible to configure translations for the login process in web applications when the identity and application language of the user is not yet known. You can find these Global translations in the Settings menu.
Some language tags will be provided by default during the installation or upgrade of IAM. An administrator can change the translations, add new language tags, or delete existing ones.
The language tags used here do not, by definition, correspond with application languages used everywhere else in the Thinkwise Platform.
Browsers provide the web application with the desired language for the login process via the Accept-Language header.
The values are also known as 'Locale identifiers'. For instance: Accept-Language: fr-CH, fr;q=0.9, en;q=0.8, de;q=0.7, *;q=0.5.
The values and weights provided by the browser in this request header will be used by Indicium or the Web GUI to determine the proper translations for the
login process.
Note that these translations are not used by the Universal GUI's login screen. Login-related processes in the Universal GUI are often delegated to Indicium (for example, OpenID, 2FA, password changes, etc.).
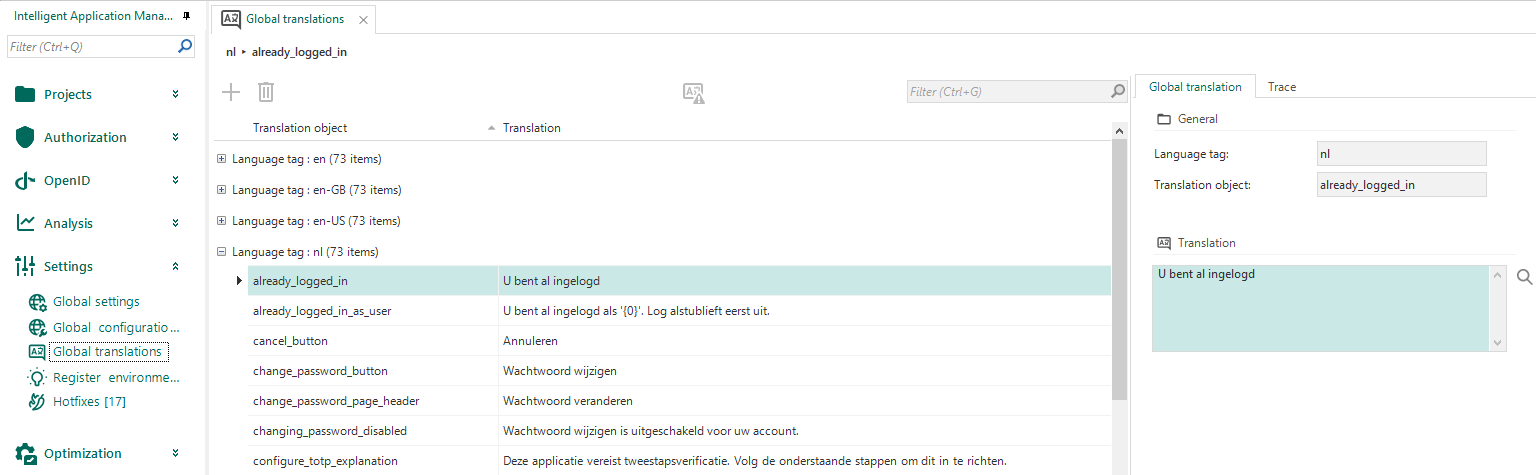 Translations for the login process
Translations for the login process
Metrics collected
As of this release, we will collect metrics regarding the usage of the Thinkwise Platform. These metrics will be used to better support our customers and partners.
The data consists of an anonymized collection of relevant information related to the use of the Thinkwise Platform. Only metadata is collected, so no personal data, no business logic, and no customer data. The data is collected from projects in IAM and the Software Factory.
This feature is optional. You can opt-out in IAM, menu Settings > Global settings > group Metrics > checkbox Send usage metrics.
Fixed
Explain task no longer responds with an error when user group name contains an &
Previously, when a user group contained an '&' character in its name, the task that explains the effective user rights would throw a seemingly random error. This has been fixed. The error will no longer pop up, and the IAM will stick to its readable messages in the information panel.
Data model changes
Data model changes for the Software Factory and IAM meta-models are listed here. This overview can be used as a reference to fix dynamic control procedures, dynamic model code or custom validations after an upgrade.
Changes Software Factory
Table changes
| SF - From table | SF - To table |
|---|---|
| - | available_hotfix |
| - | control_proc_template_statistics_dirty |
| - | execute_object_code |
| - | execute_object_code_log |
| - | generate_object_code |
| - | generate_object_code_log |
| - | icon_tag |
| - | new_object_verified |
| - | printer |
| - | unit_test_col_handler |
| execution_run | - |
| execution_run_step | - |
| printer | - |
Column changes
| SF - Table | SF - From column | SF - To column |
|---|---|---|
| automl_model_fitted | - | wall_clock_time_prediction |
| code_generation | duration | - |
| col | form_next_grp_icon | - |
| col | form_next_grp_icon_data | - |
| col | next_tab_icon | - |
| col | next_tab_icon_data | - |
| cube_view | cube_view_icon | - |
| cube_view | cube_view_icon_data | - |
| cube_view_field_conditional_layout | image | - |
| cube_view_field_conditional_layout | image_data | - |
| definition_generation | duration | - |
| definition_validation | duration | - |
| deployment_run | duration | - |
| disk_sync_job | duration | - |
| disk_sync_job_step | duration | - |
| dom | - | show_local_time |
| elemnt | picture_file | - |
| elemnt | picture_file_data | - |
| execute_source_code | - | execute_source_code_job_id |
| execute_source_code | duration | - |
| file_storage_configuration | - | file_storage_type |
| generate_sync_scripts | duration | - |
| iam_sync_job | duration | - |
| iam_sync_job_step | duration | - |
| indx | - | indx_where_clause |
| job | - | job_execution_type |
| job | duration | - |
| last_agent_check_in | - | last_downtime_recovery_utc |
| list_bar_grp | icon | - |
| list_bar_grp | icon_data | - |
| menu | icon | - |
| menu | icon_data | - |
| module_grp | icon | - |
| module_grp | icon_data | - |
| msg_option | icon | - |
| msg_option | icon_data | - |
| process | icon | - |
| process | icon_data | - |
| process_action | - | file_storage_id |
| process_action | - | printer_id |
| prog_object | - | generated_code_stale |
| project | copy_immediately | - |
| project_vrs | - | use_udt |
| project_vrs | icon | - |
| project_vrs | icon_data | - |
| report | icon | - |
| report | icon_data | - |
| report_parmtr | form_next_grp_icon | - |
| report_parmtr | form_next_grp_icon_data | - |
| report_parmtr | next_tab_icon | - |
| report_parmtr | next_tab_icon_data | - |
| report_variant | icon | - |
| report_variant | icon_data | - |
| report_variant_form | form_next_grp_icon | - |
| report_variant_form | form_next_grp_icon_data | - |
| report_variant_form | next_tab_icon | - |
| report_variant_form | next_tab_icon_data | - |
| runtime_extended_property | - | expose_to_front_end |
| screen_component | tab_page_icon_id | - |
| screen_component_type | screen_component_type_icon_id | - |
| sync_run | duration | - |
| tab | - | tree_show_label |
| tab | - | use_insert_handlers |
| tab | - | use_update_handlers |
| tab | - | use_delete_handlers |
| tab | icon | - |
| tab | icon_data | - |
| tab_prefilter | icon | - |
| tab_prefilter | icon_data | - |
| tab_prefilter_grp | icon | - |
| tab_prefilter_grp | icon_data | - |
| tab_report | - | report_display_type |
| tab_task | - | task_display_type |
| tab_variant | - | tree_show_label |
| tab_variant | icon | - |
| tab_variant | icon_data | - |
| tab_variant_form | form_next_grp_icon | - |
| tab_variant_form | form_next_grp_icon_data | - |
| tab_variant_form | next_tab_icon | - |
| tab_variant_form | next_tab_icon_data | - |
| tab_variant_report | - | report_display_type |
| tab_variant_task | - | task_display_type |
| task | - | repeat_after_execute |
| task | icon | - |
| task | icon_data | - |
| task_parmtr | form_next_grp_icon | - |
| task_parmtr | form_next_grp_icon_data | - |
| task_parmtr | next_tab_icon | - |
| task_parmtr | next_tab_icon_data | - |
| task_variant | - | repeat_after_execute |
| task_variant | icon | - |
| task_variant | icon_data | - |
| task_variant_form | form_next_grp_icon | - |
| task_variant_form | form_next_grp_icon_data | - |
| task_variant_form | next_tab_icon | - |
| task_variant_form | next_tab_icon_data | - |
| test_case_run | duration | - |
| test_run | duration | - |
| test_unit_test | duration | - |
| tile_grp | icon | - |
| tile_grp | icon_data | - |
| unit_test_result | duration | - |
| write_code_files_to_disk_job | duration | - |
| write_code_files_to_disk_job_step | duration | - |
| write_prog_objects_to_disk_job | duration | - |
Changes Intelligent Application Manager
Table changes
| IAM - From table | IAM - To table |
|---|---|
| - | available_hotfix |
| - | global_transl |
| - | global_transl_object |
| - | iam_printer |
| - | lang_tag |
| - | notification |
| - | openid_audit_log |
| - | openid_provider |
| - | openid_provider_claim |
| - | openid_provider_scope |
| - | openid_provider_usr_template |
| - | openid_provider_usr_template_appl_lang_claim_mapping |
| - | openid_provider_usr_template_gender_claim_mapping |
| - | openid_provider_usr_template_tenant_claim_mapping |
| - | openid_provider_usr_template_time_zone_claim_mapping |
| - | openid_provider_usr_template_usr_grp |
| - | openid_provider_valid_issuer |
| - | sf_printer |
| - | time_zone |
Column changes
| IAM - Table | IAM - From column | IAM - To column |
|---|---|---|
| col | - | show_local_time |
| elemnt | picture_file | icon |
| elemnt | picture_file_data | icon_data |
| global_settings | - | usr_notification_retention |
| global_settings | - | enable_local_login_option |
| global_settings | - | allow_remote_monitoring |
| global_settings | - | next_send_metrics |
| iam_extended_property | - | expose_to_front_end |
| openid_client | - | require_pkce |
| process_action | - | file_storage_id |
| process_action | - | printer_id |
| report_parmtr | - | show_local_time |
| sf_extended_property | - | expose_to_front_end |
| tab | - | use_insert_handlers |
| tab | - | use_update_handlers |
| tab | - | use_delete_handlers |
| tab | - | tree_show_label |
| tab_report | - | report_display_type |
| tab_task | - | task_display_type |
| tab_variant | - | tree_show_label |
| tab_variant_report | - | report_display_type |
| tab_variant_task | - | task_display_type |
| task | - | repeat_after_execute |
| task_parmtr | - | show_local_time |
| task_variant | - | repeat_after_execute |
| usr_authentication | - | openid_provider_id |
| usr_general | - | time_zone_id |
| usr_grp_usr | - | openid_provisioned |
| write_back_up_type | - | time_zone |