2022.1
Support for this release has ended. The release notes are still available for reference, however, no additional updates will be provided. Update to the latest version. See our Lifecycle policy for more information.
The 2022.1 release of the Thinkwise Platform features a lot of additions and improvements, and a large number of feature requests and tickets have been addressed.
Table of contents
- Table of contents
- Upgrade notes
- Software Factory
- Breaking
- New
- Download and install solutions from the Thinkstore
- Deployment processes redesigned
- Creation: Write program objects to disk available again
- Creation: new and changed in Execute source code
- Expandable validation messages in the tree
- Import and export projects for reuse
- Process flows: custom schedules for system flows in IAM
- Process flows: cleaning up old process flow schedule log items
- Process flows: new process action
- Functionality: prefilter for disapproved control procedures
- Procedure to wait for job completion
- New logic concept: change detection
- New: Thinkwise Upcycler
- Quality: tab Unit tests added to Code review screen
- New validations
- Changed
- Settings menu renamed, Jobs screen added
- Runtime configuration only active for branch creator
- Moved unassigned work will be assigned to current user
- Name of logged-in user visible in the Universal GUI
- Choose RDBMS type while creating a new project
- Translations: exclude non-translated objects from "Not yet approved" prefilter
- Increased field width for Task popups with Host and Database fields
- Removed
- Fixed
- Intelligent Application Manager
- Data model changes
Upgrade notes
SQL Server and .NET Framework support
-
The Software Factory development environment and the Intelligent Application Manager require SQL Server 2017 or higher.
Read about the end of SQL Server 2016 support here: https://community.thinkwisesoftware.com/news-updates-21/end-of-sql-server-2016-support-2344
-
This also applies to the Windows and Web user interfaces, which additionally need version 4.7 minimum of the .NET Framework (4.7.2 is advised for Web).
-
The Indicium application tier requires SQL Server 2017 or higher and .NET 5.0 Indicium Legacy requires .NET Framework 4.7.2. For more information please check the Indicium documentation.
For more information about supported technologies, see the Thinkwise Lifecycle Policy.
Upgrading from 2020.1 or earlier
If you're upgrading from version 2020.1 or earlier, it is required to upload all image and report files to the database once. More information about uploading images and reports can be found here: Images and reports should be uploaded
Software Factory
Breaking
Check project folder
Due to the redesigned deployment process, various files can be written to disk. Please check whether this location is available to Indicium. If not, the process will fail and an error will occur. The project folder location can be changed in menu Project > Project overview > tab Project versions > tab Form > field Project folder specification.
Thinkwise advices to use a UNC path here.
Changing the project folder affects the file locations of your entire project.
It concerns the following processes and tasks in menu Deployment:
- menu item Creation > tab Generate source code > task Generate source code > option Write program objects to disk. After a successful run, these files are written to
project folder\Source_code\Program_objects. - menu item Creation > Step Generate source code > task Generate source code > option: Write code files to disk. After a successful run, these files are written to
project folder\Source_code\Groups. - menu item Synchronization to IAM > task Synchronize to disk (previously: Write to disk). After a successful run, the script is written to
project folder\MODEL_SYNC.sql. - menu item Deployment package > task Create deployment package. After a successful run, all deployment package files are written to the
project folder\Deployfolder.
New
Download and install solutions from the Thinkstore
In this release, we have fully integrated the Thinkstore into the Software Factory. Now, you can download and install ready-made solutions directly into your projects. This highly improves working with the Thinkstore.
The Thinkstore is already available in the Community. It contains a collection of scripts and samples to help you get the most out of the Thinkwise Platform. Here, you can manually download and execute or copy/paste them into your application.
In the Software Factory, the Thinkstore used to be available through a button in the Project ribbon. Now, you can access it from the menu Enrichment > Thinkstore. Here, you can select and install samples and models right from the Thinkwise IDE into your projects.
To pick the right solution, you can make an initial selection by category and industry, using the checkboxes on the left of the Thinkstore screen. Prefilters are available for further selection on work or base projects. To make your final selection, you can use the combined filter, description, or blue tags on the right.
If you have found a solution you want to try, you can download it by logging in with your TCP account and consenting to the application. Then, you can install the solution. You need to provide the project name and version in a task pop-up. These must be the same as the project name and version in the Software Factory. If the solution is a base project, you can link it to a project.
Status icons will show the download and installation progress. You can install a solution multiple times under different project names and project versions.
After installing, do not forget to generate the definitions for your project containing the newly linked project.
The Thinkstore only contains solutions specifically for the Software Factory version you are using. Therefore, the Thinkstore will be cleared before every platform upgrade. Once upgraded and opening the Thinkstore in the new Software Factory version, it will initiate a refresh and retrieve all available solutions for that version.
Note that the Thinkstore button has also been removed in older versions of the Software Factory.
In the future, it will be possible to upload your own samples from your own development environment to the Thinkstore repository to help your fellow developers. Would you like to add your solution to the Thinkstore now? Then submit your Idea to the Community, for Product area 'Thinkstore'.
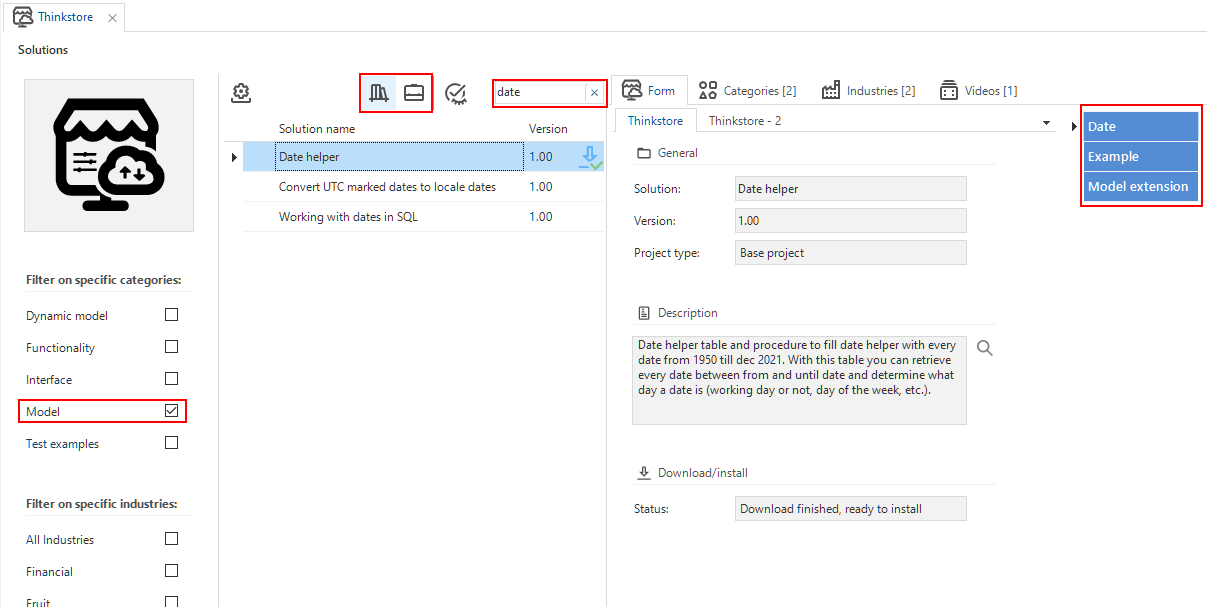 Select the solution you need in the Thinkstore
Select the solution you need in the Thinkstore
Deployment processes redesigned
In addition to the redesigned Creation process (see the previous release, 2021.3), the synchronization to IAM and creation of deployment packages have also been redesigned. Both processes now also run through Indicium so they can be automated via the Indicium API.
The synchronization to IAM is available in the Software Factory via the menu Deployment > Synchronization to IAM. On this screen, you can start new runs to synchronize your projects. You can also follow the progress here.
- In the task Synchronize to IAM, you no longer need to enter a host, database, or authentication. Instead, you only need to select a Target IAM (as set in the menu Maintenance > IAM configurations).
- In the task Synchronize to disk (previously: Write to disk), you no longer need to enter a file location. After a successful run, the script is written
to
project folder\MODEL_SYNC.sql. A field containing the location appears on the screen. You can easily navigate to this file or folder using the buttons next to it. - In both tasks, the new Note field allows you to place a comment, like the reason for synchronizing. This comment is visible in the History tab's grid.
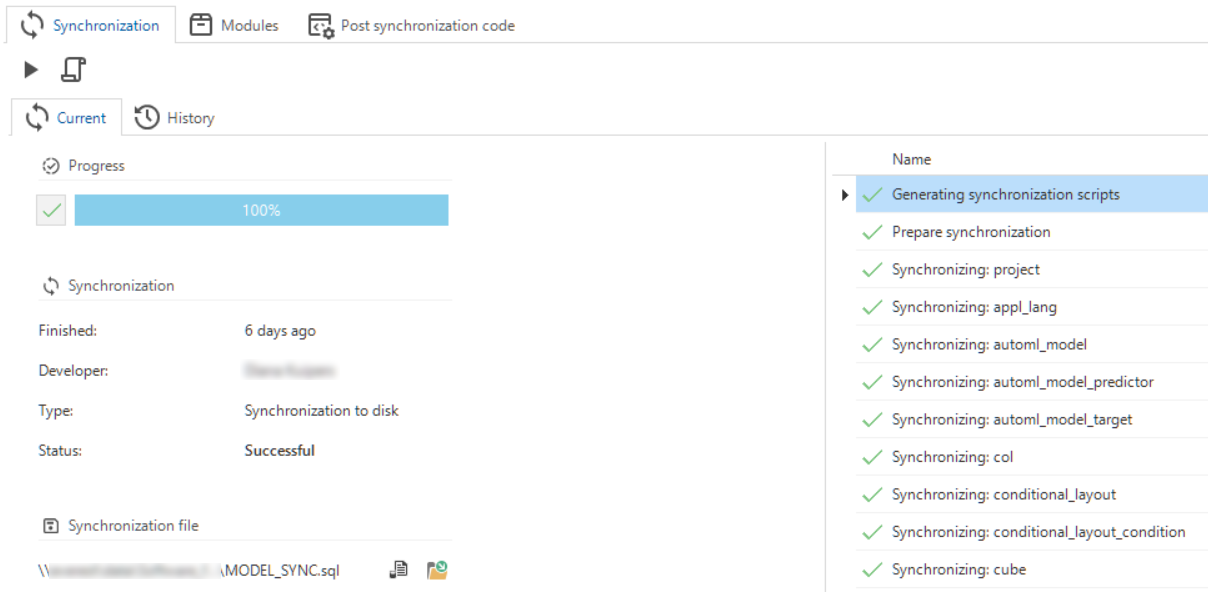 The redesigned synchronization to IAM process
The redesigned synchronization to IAM process
The creation of deployment packages is available in the Software Factory via the menu Deployment > Deployment package. In this screen, you can start new runs to deploy your projects. You can also follow the progress here.
- You no longer need to enter a file location. After a successful run, all deployment package files are written to the
project folder\Deployfolder. A field containing the location appears on the screen. You can easily navigate to this folder using the button next to it. - The new Note field allows you to place a comment, like the reason for creating the deployment package. This comment is visible in the History tab's grid.
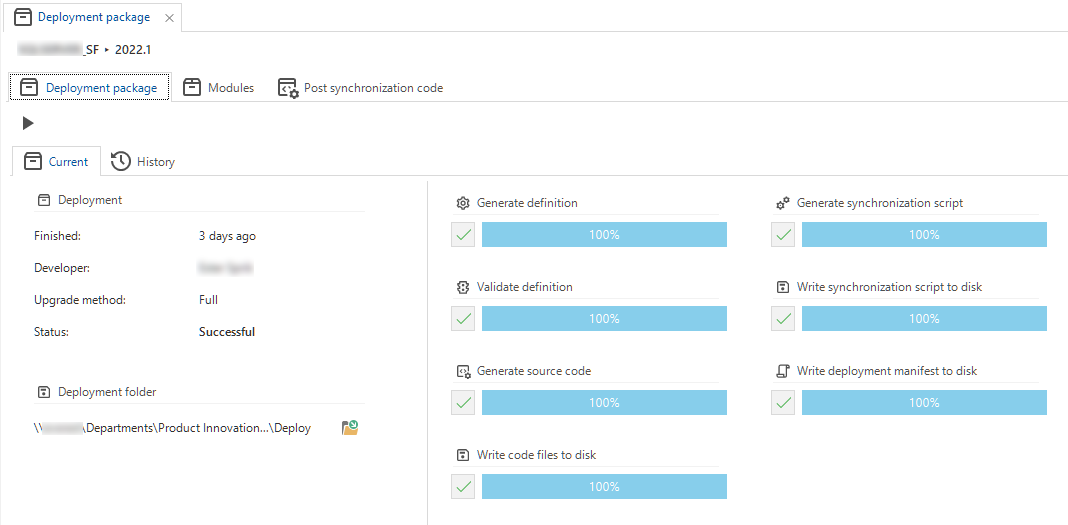 The redesigned deployment package process
The redesigned deployment package process
Creation: Write program objects to disk available again
In the previous release (2021.3), the option to write program objects to disk had been removed in the redesigned Creation process.
Now, it is available again, in the menus:
- Deployment > Creation > tab Generate source code
- Deployment > Creation > tab Generate definition > task Execute all steps.
After a successful run, these files are written to project folder\Source_code\Program_objects. A field containing the exact location appears on the
corresponding screen. You can navigate to this folder using the button next to it.
The same applies to the Write code files to disk option. These files are written to project folder\Source_code\Groups.
Creation: new and changed in Execute source code
In the Execute source code step in the Creation process, we have improved functionality and added some new features.
Firstly, we have improved the information on the user input that is sometimes required when the execution is aborted. Now, it is explained in the grid which action is expected:
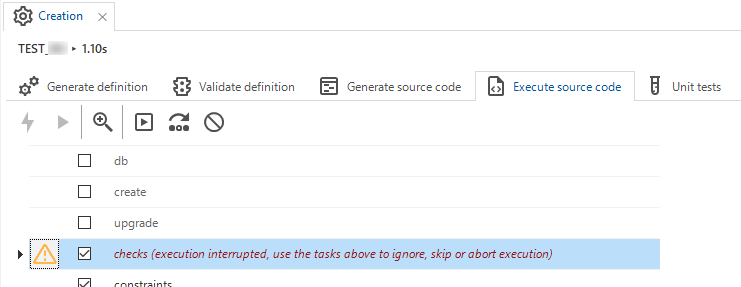 Explanation of the required user input
Explanation of the required user input
In addition, we have improved the icons for the available tasks to continue the execution:
 Ignore error and continue current code file execution.
Ignore error and continue current code file execution. Skip code file and continue execution.
Skip code file and continue execution. Abort execution.
Abort execution.
New in the Execute source code step is the option to determine the error handling behavior in API calls. As of the previous release, it was already
possible to automate the Execute source code job via Indicium's API. Now, you can add error_handling as a parameter to the following tasks:
- Connect to database (task_connect_to_db).
- Execute source code (task_add_job_to_execute_source_code).
You can use the following values to determine the type of error handling:
- 0 - Abort the code execution.
- 1 - Ignore the current code file and resume execution from the next code file.
- 2 - Retry the current code file and resume execution from the next statement after the error occurred.
- 3 - Suspend the code execution and wait for user input.
Added to this, the error log has been improved when the source code is executed via the user interface or Indicium's API. Previously, during the execution of source code, the log used to show errors together with the query that was run. However, some queries can be fairly large and flood the log. That resulted in an unreadably long log. To improve this, only the last error is shown during the execution of the source code. After the job completes, whether it succeeded, failed, canceled, or aborted, the full log is displayed with all errors and informative messages.
Expandable validation messages in the tree
Validations will now only show the first 25 messages. This benefits the performance and overview of the screen. When there are more than 25 messages, a node to expand the validation is added to the tree. You can expand the list by using the 'Expand validation' task or by double-clicking the node (+) in the tree. Then, all messages are shown until the validation is executed again.
![]() Expand validation icon
Expand validation icon
 Expandable validations
Expandable validations
It is also possible to view all messages in the detail tab instead of the tree. The detail tab contains the same tasks, prefilters, and Related object tab as the validation messages in the tree. In addition, it provides more options to filter specific messages than the tree. With the prefilter Hide messages you can hide the messages in the tree view.
This new solution means you can choose to keep one overview in the tree or to keep the tree more compact and clean by solving the messages in the grid view. You can choose what works best for you.
 Validations in a detail tab
Validations in a detail tab
Import and export projects for reuse
It's now possible to export and import your own work and base projects in the Software Factory. By exporting a project, you can share it between different environments. This is a fast and easy way to enrich your projects.
Note that you can only import a project in another Software Factory if the version is the same as the Software Factory the project was exported from.
Tasks for exporting and importing are available in menu Projects > Project overview > tab Project versions > tab List.
 Export project version - To export a project version, you first need to specify a project folder in the grid.
Then, you can start the export. The complete project version model will be exported excluding trace columns and non-default runtime configurations. The project
will be compressed, named model.dat, and written to the selected project folder.
Export project version - To export a project version, you first need to specify a project folder in the grid.
Then, you can start the export. The complete project version model will be exported excluding trace columns and non-default runtime configurations. The project
will be compressed, named model.dat, and written to the selected project folder. Import project version - To import a project, select the file path for the model.dat file you wish to import.
The project will be decompressed and imported. Trace columns will be filled with the user name 'Imported' and the current system DateTime.
Import project version - To import a project, select the file path for the model.dat file you wish to import.
The project will be decompressed and imported. Trace columns will be filled with the user name 'Imported' and the current system DateTime.
Process flows: custom schedules for system flows in IAM
Community ideaPreviously, if you wanted to deviate from a set schedule for a system flow, you had to create a new one or alter the existing one in the Software Factory and synchronize it to IAM. Now, you can create custom schedules for system flows directly in IAM.
First, you need to allow using a custom schedule in the system flow in the Software Factory by checking the Custom schedule allowed box in menu Processes > Process flows. This checkbox is only available for system flows. Disabling it will not delete any existing custom schedule for the system flow in IAM.
 Allowing a custom schedule in the Software Factory
Allowing a custom schedule in the Software Factory
Then, as a root administrator, you can create a custom schedule for the system flow in IAM, in menu Authorization > Applications > Scheduled system flows > Schedules.
When copying an application to the next version of the project, custom schedules will be copied automatically if the system flow still exists.
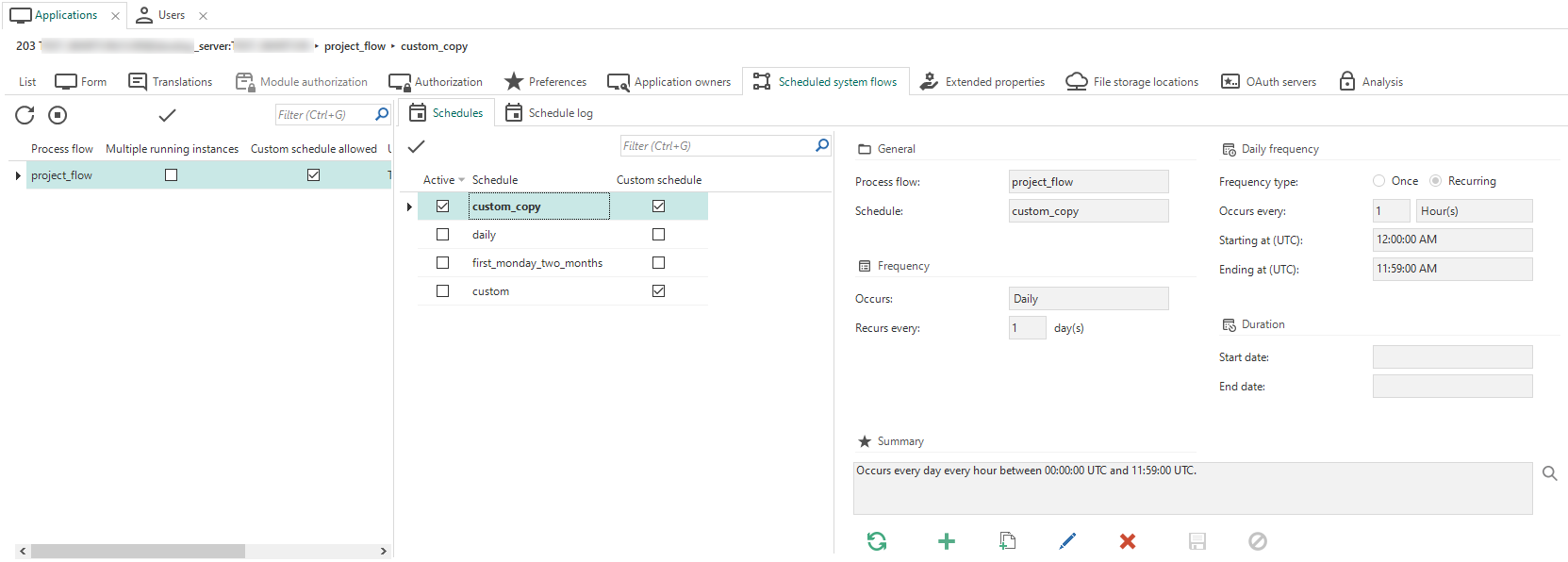 A custom schedule for a system flow in IAM
A custom schedule for a system flow in IAM
Process flows: cleaning up old process flow schedule log items
The Software Factory uses system flows for all Creation steps and Synchronization to IAM. As a result, the process flow schedule log in IAM receives log items every 10 seconds. This takes up database space. Moreover, it may not be necessary to keep the log items for a long time.
Therefore, a new system flow will now automatically empty the log every five minutes up to a set amount of log items. You can set the minimum amount of log items you wish to keep in IAM, menu Settings > Global settings > field Log retention (items). This value is set to 100 items by default but can be changed. Since the log is also used by Indicium, one item is the minimum amount.
 Set the number of log items you wish to keep
Set the number of log items you wish to keep
This limited log retention is activated by default, but you can turn it off (and back on) for specific system flows in the Schedule log in IAM:
- menu Authorization > Applications > tab Scheduled system flows > tab Schedule log or
- menu Analysis > Scheduled system flows > Schedule log.
Reactivating log retention will automatically empty the log file to the set amount in IAM.
Process flows: new process action
Community ideaIt is now possible to generate reports via system flows and use the returned report data in, for example, a Write file connector. This new process action is called Generate report. It will not use any default or layout procedures attached to the report. This process action has three fixed output parameters: Status code, File name (text), and Report data (binary).
Functionality: prefilter for disapproved control procedures
Community ideaWe have added a prefilter to the Functionality screen that gives you an overview of all disapproved control procedures assigned to the developer. As a result, the In development prefilter will no longer show disapproved control procedures.
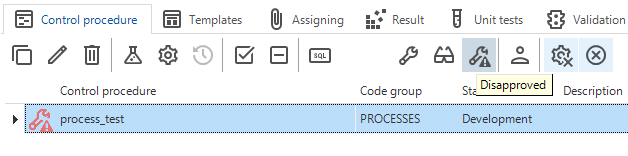 Prefilter for disapproved control procedures
Prefilter for disapproved control procedures
Procedure to wait for job completion
All tasks add_job_to_... stored procedures now return the (last) created job_id through an output parameter. In addition, a procedure called wait_for_job
has become available that you can use to wait for a given job. Once that job has finished, the procedure will end automatically.
With this procedure, you can ensure that available processes that run through jobs, like Generate definition, wait until the completion of the job before continuing execution.
New logic concept: change detection
Windows GUI Web GUIWe have added a new logic concept: Change detection. It allows you to inform the user interfaces during certain events whether or not a subject has been changed and needs to be refreshed. This logic is only available for subjects, such as tables and views. It is not available for tasks and reports as they have no data.
In the Thinkwise Platform, we are using this, for example, in the validation screen in the Creation process. It ensures that the screen only refreshes during the validation process.
The logic can be enabled at a subject's configuration (menu User interface > Subjects > tab Settings > tab Performance > checkbox Change detection). Once enabled, the Change detection logic can also be called directly via the API.
Enabling this logic without assigning any code will effectively disable auto-refresh.
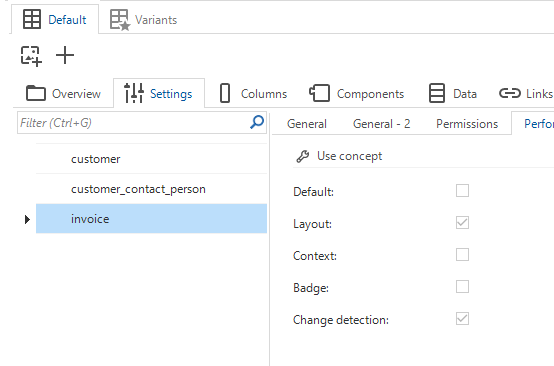 Checkbox for enabling Change detection
Checkbox for enabling Change detection
The Change detection mechanism is only used in conjunction with the auto-refresh functionality. Every time an auto-refresh is performed, the user interface can call this logic concept to conditionally prevent it.
In future releases, this logic may be leveraged (opt-in) to ignore user-initiated refreshes as well, thus limiting users who refresh certain subjects. This logic is also a candidate to be leveraged for decisions regarding refreshing offline data.
You can use the CHANGE_DETECTION code group for a control procedure to assign logic for change detection.
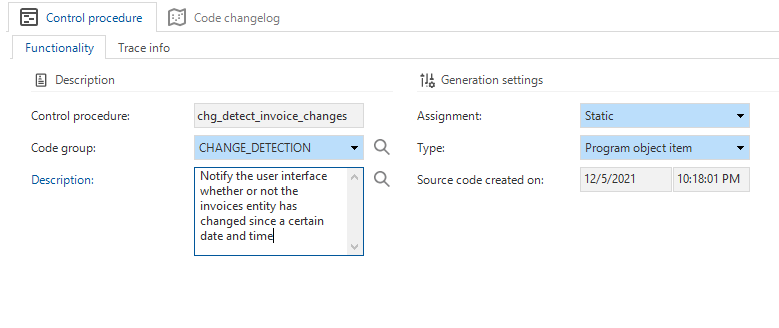 The CHANGE_DETECTION code group
The CHANGE_DETECTION code group
New: Thinkwise Upcycler
Thinkwise has upcycled many legacy applications in many different technologies over the years. In this release, by introducing the Thinkwise Upcycler, we make our knowledge available as a product that you can use for modernizing your legacy applications.
The goal of the Thinkwise Upcycler is to jump-start the modernization of your existing legacy application. It completely replaces the legacy application and migrates its data automatically to a modernized application, with a fully responsive web app user interface and an integrated service tier. After upcycling your legacy application, you can further develop your new application. Depending on the legacy technology used, the Thinkwise Upcycler saves 20 to 50 percent development time.
For a successful replacement of your legacy application, you need a team with the expertise of your application, your legacy technology, and the Thinkwise platform. Please, contact Thinkwise or a Certified Partner for more information.
The Thinkwise Upcycler comes with Upcyclers for relational databases Microsoft SQL Server, DB2, Progress OpenEdge, PostgreSQL, and the Uniface platform. It also enables you to develop Upcyclers for other technologies and tailor all Upcyclers to your specific needs.
When you want to modernize your legacy application, the first step is to derive metadata. This will save a lot of time later in your project. The Upcycler derives as much metadata as possible from your legacy application with a utility program. This program extracts the metadata from your legacy application and then transfers them into a file suitable for the Thinkwise Upcycler. For some legacy technologies, the export facilities of that technology are used instead.
The Thinkwise Upcycler supports the use and development of Upcyclers for different technologies. An Upcycler is a series of steps implemented in SQL that convert your source metadata into metadata for the Software Factory. You can find these steps in three levels that inherit from each other:
- The Generic level gives you an easy start in defining your own Upcycler.
- The Technology level is where you define your Upcycler for a specific type of legacy technology. At this level, several Upcyclers are available that have already been developed by Thinkwise. The Technology level inherits from the Generic level.
- The Application level is where you tailor a technology Upcycler for a specific application. The Application level inherits from the Technology level.
The Data Importer is structured in the same way.
In the Thinkwise Docs, information will soon be available on the Thinkwise Upcycler, the Upcyclers it provides, and the metadata extraction tool.
Quality: tab Unit tests added to Code review screen
Community ideaWhen reviewing control procedures, it is helpful to run the accompanying unit tests to ensure the code is running as intended. Therefore we added the Unit tests tab to the Code review screen (menu Quality > Code review). A badge displays the number of unit tests available for the control procedure.
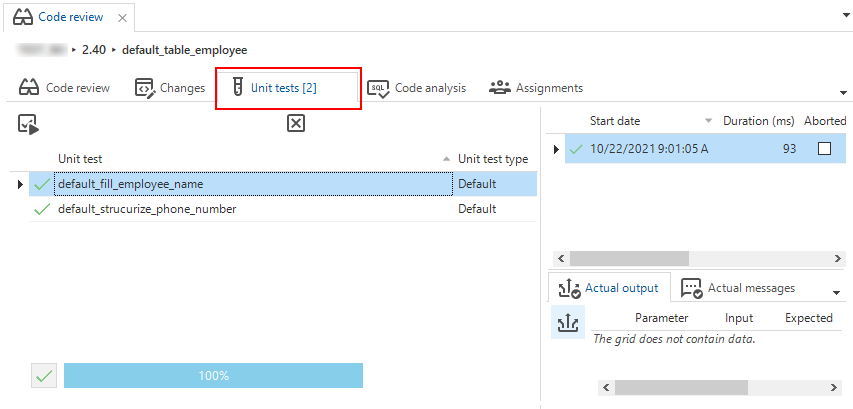 Tab for unit tests in code review screen
Tab for unit tests in code review screen
New validations
- A validation has been added to check for the use of an expression field as a partition column since these columns are not stored in the database. The Partition settings are available in the menu Data > Data model > tab Tables > tab Form.
- A set of new validations have been created to check that default values correspond to the data type of the column or parameter. During development, data types for columns or parameters may change and consequently no longer correspond to their data type.
- Two validations for prefilters have been created to check whether the chosen filter condition uses the filter value (and filter value until) column(s).
Changed
Settings menu renamed, Jobs screen added
The menu group Settings has been renamed to the more comprehensive Maintenance.
In addition, the Jobs screen has been added to this menu group. This screen contains an overview of all available jobs and agent statistics and used to be part of the Advanced menu.
Runtime configuration only active for branch creator
Previously, when creating a branch, all runtime configurations were copied to it, including active runtime configurations for users. As a result, the branch project was available in the Project tab in the top bar for all those users. This result was undesired and has therefore changed.
Now, only the creator of the branch will have access to the active runtime configuration. All other users can activate the runtime configuration for this branch in the menu Settings > Users. Here you can select the user and find the corresponding runtime configuration in the tab Runtime configurations.
Moved unassigned work will be assigned to current user
When unassigned work is moved from one lane into another inside the Taskboard (menu Specification), it will now be assigned to the current user. This does not apply if work is moved into an inactive lane.
Name of logged-in user visible in the Universal GUI
Community ideaWhen the Universal GUI is started against the Software Factory, it shows the first and last name of the logged-in user. Since those fields are not available in
the Software Factory, we used the usr_id field to display the name of the logged-in user. This has been changed. Now, we show the name as set in menu
Settings > Users > field Name.
Choose RDBMS type while creating a new project
When you create a new project, it is now possible to choose the RDBMS type for the application. The default is set in the menu Maintenance > Configuration.
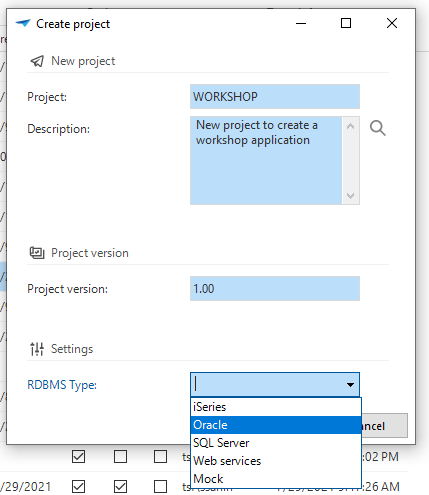 Select the RDBMS Type in a new project
Select the RDBMS Type in a new project
Translations: exclude non-translated objects from "Not yet approved" prefilter
The prefilter Not yet approved will now exclude non-translated objects. This makes it easier to approve only the actual translations.
Increased field width for Task popups with Host and Database fields
To accommodate the longer names of cloud platform hosts and databases, we have increased the field width in task pop-ups. Not only when synchronizing to IAM, but for all tasks containing a Host and Database field.
Removed
Field Tile image removed
In the subject settings (menu User interface > Subjects > tab Default > tab Settings), the field Tile image has been removed. The reason is that the Tile menu already supports SVG icons, which has made this field redundant.
In this release, an upgrade script will ensure that tile images are migrated to the Icon field in the same tab if no icon is present yet. If icons in the document or container tabs are not desired, you can disable the Show icon option in menu User interface > Themes > tab General > tab Tabs > tab Document/Container tab > field Icon - Show.
Control procedures: unused columns removed
The following columns in the Control procedure tab (for example, in the menu Business logic > Functionality) are no longer used and have been removed:
- reviewed
- reviewer_id
- reviewed_date_time
- tested
- tester_id
- tested_date_time
- priority.
Views: 'View order by clause' removed from auto-generated views
The option View order by clause has been removed from auto-generated views (menu Data > Data model > Tables > Form). View code should not contain an order by clause since it leads to poor performance and a high server load.
Function dbo.get_look_up_query removed
The function dbo.get_look_up_query has been removed since it was no longer used by the Software Factory. Developers using this function in their code will
need to alter their code to prevent errors.
Fixed
Error when entering large numbers into fields with tinyint or smallint datatypes
When entering larger numbers into fields with tinyint or smallint datatypes than they can handle, the Universal GUI would raise an error. To prevent this, the Thinkwise Platform will ensure that the minimum and maximum values are always returned to the Universal GUI for fields with these data types, even when not manually set in the model. The minimum value will be 0, and the maximum value will be the maximum the data type can handle; 255 for tinyint and 32767 for smallint.
Program object assignments not renamed after renaming process flow
When renaming a process flow, the program object assignments were not renamed, and therefore no longer assigned to the object. This has been fixed. Now, when
renaming a process flow, the assignments will also be renamed. After the code group PROCESSES has been generated, the assignments can be deployed.
Check constraints with more than 4000 characters were limited
When a check constraint had more than 4000 characters, the program object item parameter would limit it to 4000 characters. This has been fixed. Now, check constraints with more than 4000 characters can be applied to the database successfully.
Intelligent Application Manager
New
Task to copy user and group preferences
It is now possible to copy all preferences to selected users or user groups by executing the new Copy preferences task. This task is available for Main administrators only in the screens Authorization > Users and Authorization > User groups. In a popup, you can select the user or user group whose preferences you want to copy.
![]() Task to copy preferences for users and user groups
Task to copy preferences for users and user groups
Fixed
Duplicate key error while synchronizing to IAM
While synchronizing models to IAM, a Duplicate key error could occur due to a data type that allowed only 100 characters. The data type now allows 500 characters, so the error cannot occur any longer.
Data model changes
Data model changes for the Software Factory and IAM meta-models are listed here. This overview can be used as a reference to correct own written code, such as:
- Dynamic control procedures
- Dynamic model code
- Post-sync/deployment code
- Custom validations
In this release, 12 domains have been altered to allow the Upcycler to utilize the full size of SQL sysnames. If you use any of these domains in your code, we advise checking your code for possible overflows of data types.
The affected domains are: col_id, dom_id, object_name_id, report_id, report_parmtr_id, sub_name_id, subroutine_id, subroutine_parmtr_id,
subroutine_return_col_id, tab_id, task_id and task_parmtr_id.
Changes Software Factory
Table changes
| SF - From table | SF - To table |
|---|---|
| - | audio_file |
| - | deployment_run |
| - | deployment_run_step |
| - | disk_sync_job |
| - | disk_sync_job_log |
| - | disk_sync_job_step |
| - | generate_sync_scripts |
| - | generate_sync_scripts_step |
| - | iam_sync_job |
| - | iam_sync_job_log |
| - | iam_sync_job_step |
| - | icon |
| - | subroutine_parmtr_tag |
| - | sync_run |
| - | sync_script |
| - | sync_target_iam |
| - | thinkstore |
| - | thinkstore_category |
| - | thinkstore_category_filter |
| - | thinkstore_dependent_on_solution |
| - | thinkstore_industry |
| - | thinkstore_industry_filter |
| - | thinkstore_media |
| - | thinkstore_tag |
| - | validation_modeler |
| - | write_code_files_to_disk_job |
| - | write_code_files_to_disk_job_log |
| - | write_code_files_to_disk_job_step |
| - | write_prog_objects_to_disk_job |
| - | write_prog_objects_to_disk_job_log |
| - | write_prog_objects_to_disk_job_step |
Column changes
| SF - Table | SF - From column | SF - To column |
|---|---|---|
| col | - | form_next_grp_icon_id |
| col | - | next_tab_icon_id |
| col | grid_col_width_manual | - |
| control_proc | priority | - |
| control_proc | reviewed | - |
| control_proc | reviewer_id | - |
| control_proc | reviewed_date_time | - |
| control_proc | tested | - |
| control_proc | tester_id | - |
| control_proc | tested_date_time | - |
| cube_view | - | cube_view_icon_id |
| cube_view_field_conditional_layout | - | image_id |
| elemnt | - | icon_id |
| execute_source_code_log | - | last_execute_source_code_log |
| job | - | duration |
| list_bar_grp | - | icon_id |
| menu | - | icon_id |
| module_grp | - | icon_id |
| msg | - | audio_file_id |
| msg_option | - | icon_id |
| process | - | icon_id |
| process | tile_image | - |
| process | tile_image_data | - |
| process_flow | - | iam_custom_schedule_allowed |
| project_vrs | - | icon_id |
| report | - | icon_id |
| report | tile_image | - |
| report | tile_image_data | - |
| report_parmtr | - | form_next_grp_icon_id |
| report_parmtr | - | next_tab_icon_id |
| report_variant | - | icon_id |
| report_variant | apply_tile_image | - |
| report_variant | tile_image | - |
| report_variant | tile_image_data | - |
| report_variant_form | - | form_next_grp_icon_id |
| report_variant_form | - | next_tab_icon_id |
| screen_component | - | tab_page_icon_id |
| screen_component_type | - | screen_component_type_icon_id |
| sf_configuration | - | next_thinkstore_update_utc |
| sf_configuration | - | thinkstore_update_pending |
| sf_configuration | - | thinkstore_refresh_token |
| tab | - | icon_id |
| tab | - | use_change_detection |
| tab | view_order_by | - |
| tab | tile_image | - |
| tab | tile_image_data | - |
| tab_prefilter | - | icon_id |
| tab_prefilter_grp | - | icon_id |
| tab_variant | - | icon_id |
| tab_variant | apply_tile_image | - |
| tab_variant | tile_image | - |
| tab_variant | tile_image_data | - |
| tab_variant_form | - | form_next_grp_icon_id |
| tab_variant_form | - | next_tab_icon_id |
| tab_variant_grid | grid_col_width_manual | - |
| task | - | icon_id |
| task | tile_image | - |
| task | tile_image_data | - |
| task_parmtr | - | form_next_grp_icon_id |
| task_parmtr | - | next_tab_icon_id |
| task_variant | - | icon_id |
| task_variant | apply_tile_image | - |
| task_variant | tile_image | - |
| task_variant | tile_image_data | - |
| task_variant_form | - | form_next_grp_icon_id |
| task_variant_form | - | next_tab_icon_id |
| test_case_run | - | duration |
| test_case_run | end_date_time | finish_date_time |
| test_case_run | total_time_elapsed | - |
| test_run | - | duration |
| test_run | end_date_time | finish_date_time |
| test_run | total_time_elapsed | - |
| test_step_run | total_time_elapsed | duration |
| tile_grp | - | icon_id |
| transl_object_transl | verified | approval_status |
| unit_test_result | end_date_time | finish_date_time |
| unit_test_result | host | server_name |
| usr | - | write_prog_objects |
| usr | - | active |
| usr | priority | - |
| usr | analyst | - |
| usr | designer | - |
| usr | developer | - |
| usr | reviewer | - |
| usr | tester | - |
| validation | abs_order_no | - |
| validation | verified | approval_status |
| validation_grp | abs_order_no | - |
| validation_msg | - | validation_msg_description |
Changes Intelligent Application Manager
Table changes IAM
| IAM - From table | IAM - To table |
|---|---|
| - | iam_process_flow_schedule |
| - | system_flow_excluded_from_log_clean_up |
| process_flow_schedule | sf_process_flow_schedule |
| project_admin | - |
| project_manager | - |
| theme_splash | - |
Column changes IAM
| IAM - Table | IAM - From column | IAM - To column |
|---|---|---|
| global_settings | - | system_flow_log_retention |
| global_settings | - | environment_registered |
| global_settings | pending_system_flow_interval | system_flow_agent_polling_interval |
| msg | - | audio_file |
| msg | - | audio_file_data |
| sf_process_flow | - | iam_custom_schedule_allowed |
| tab | - | use_change_detection |
| tab | tile_image | - |
| tab | tile_image_data | - |
| tab_variant | tile_image | - |
| tab_variant | tile_image_data | - |
| usr_pref_model_tab_prefilter_status | - | type_of_path |